AIモデルルーティングとは?AIモデルルーティングとマルチモデルAIインフラストラクチャについて解説
AIアプリケーションやAIエージェントの進化が加速する中、マルチモデルAIアーキテクチャの導入が広がっています。各AIモデルは推論力、応答速度、コスト構造が異なり、単一モデルへの依存は過剰なコストや非効率の原因となります。そのため、AIモデルルーティングは現代AIインフラの中核技術となっています。
AIルーターは、複数モデル間でタスクをインテリジェントに割り振ることで、AIシステムの柔軟性・拡張性・安定性を向上させます。この協調的なマルチモデル運用は、AI SaaSプラットフォームやAIエージェント、自動化AIアプリケーションの中心的なアプローチとなっています。
AIモデルルーティングとは
AIモデルルーティングは、複数AIモデルへのリクエストを管理し、各タスクに最適なモデルを選択する技術的手法です。
従来のAIアプリケーションは1モデルのみと接続するのが一般的でした。たとえば、チャットボットは特定の大規模言語モデルAPIを呼び出すだけです。しかし、タスクごとに求められる要件は大きく異なります。
- テキスト要約や簡単なQ&Aは複雑な推論を必要としません
- 複雑な論理分析やコード生成には高性能モデルが不可欠です
- 多言語翻訳には言語特化型モデルが適しています
すべての処理を高性能モデルに任せるとコストが膨らみ、単純モデルに複雑な処理を割り当てると品質が損なわれます。
AIモデルルーティングは、各リクエストを分析し、最適なモデルに動的に割り当てることで、パフォーマンスとコストの最適化を実現します。
AIアプリケーションに複数モデルが必要な理由
AI技術の進化により、モデルは用途や能力ごとに特化が進んでいます。これがマルチモデルAIアーキテクチャ普及の背景です。
モデルごとに強みが異なります。あるモデルは高度な推論、別のモデルは高速処理やコスト効率に優れています。複数モデルの組み合わせにより、タスクごとに最適な選択が可能となります。
また、マルチモデル構成は運用コスト削減に寄与します。単純な処理は低コストモデル、複雑な処理は高性能モデルに割り当てることで、全体コストを大幅に抑制できます。
さらに、マルチモデル運用はシステムの信頼性向上にも有効です。特定モデルがダウンしても、別モデルでリクエスト処理を継続でき、サービスの安定稼働を確保します。
AIモデルルーティングの仕組み
AIモデルルーティングシステムは、ルーティングエンジンを用いて、各リクエストに最適なモデルを判断します。エンジンは次の観点から選択を行います。
タスクの複雑さ:リクエスト内容(プロンプト長やタスク種別など)を評価し、必要なモデル性能を判定します。
モデルの特性:モデルごとに得意分野が異なり、コード生成やマルチモーダル処理などで差が出ます。
応答速度:チャットボットやAIエージェントなどリアルタイム性が求められる場合、応答遅延の最小化が重要です。
呼び出しコスト:API利用料はモデルごとに異なるため、コストも重要な判断基準となります。
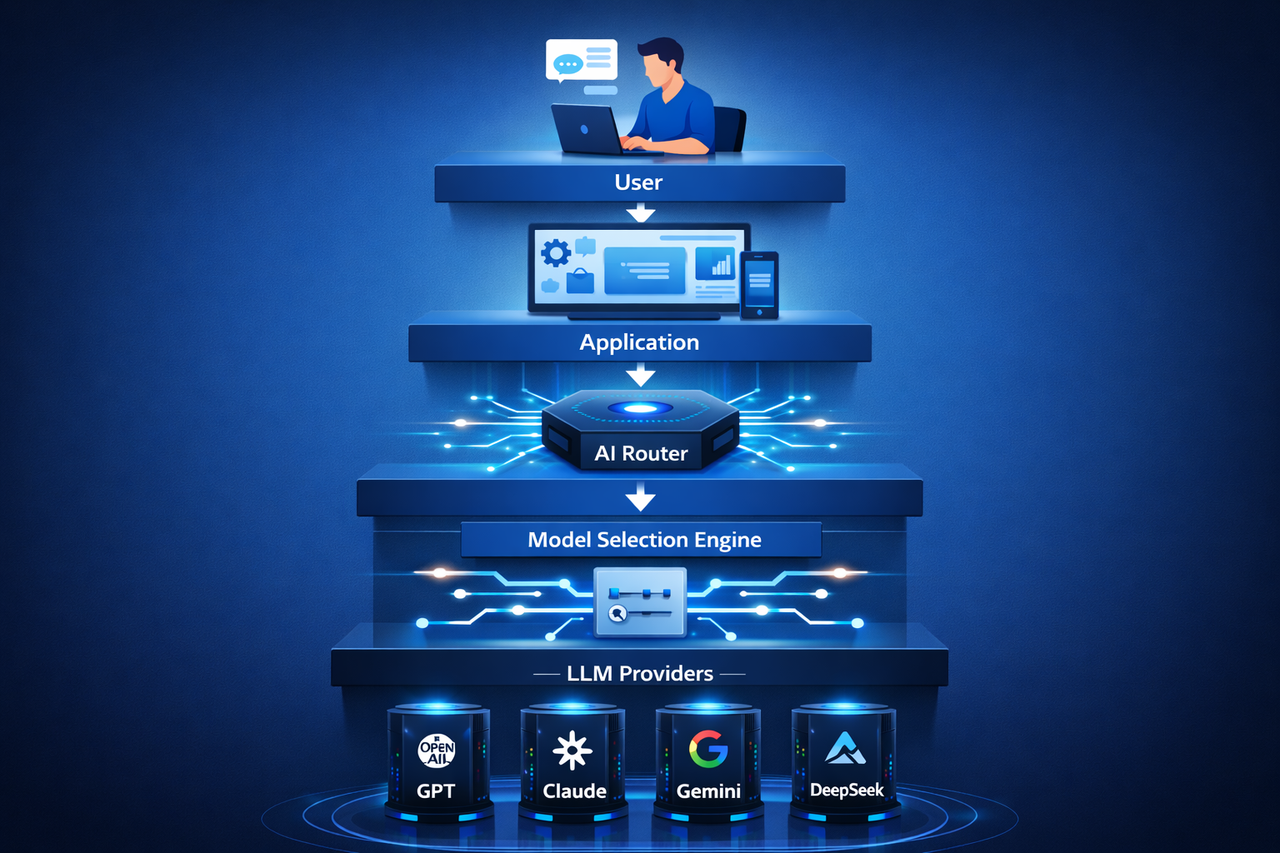
ユーザーやAIエージェントがリクエストを送信すると、AIルーターがタスクを解析し、最適なモデルを選定して結果を返します。
主要なAIルーティング戦略の比較
AIインフラの現場では、モデルルーティングにさまざまな戦略が用いられます。
コスト重視戦略:通常業務は低コストモデルで処理し、複雑なケースだけ高性能モデルを利用します。
パフォーマンス重視戦略:品質最優先で、コストが高くても最も能力の高いモデルを優先します。
ハイブリッド戦略:最新のAIルーターはコスト・性能・応答速度のバランスをとる複合型戦略を採用します。
タスク特化戦略:コード生成やマルチモーダル処理など、特定タスク専用モデルを選択する手法です。
各戦略はAIアプリケーションの特性に応じて最適化される必要があります。
AIモデルルーティングとAI APIゲートウェイの違い
AIモデルルーティングとAPIゲートウェイは役割が異なります。
AI APIゲートウェイ:APIリクエストの認証、トラフィック管理、セキュリティなどを担い、モデル選択は行いません。
AIモデルルーター:リクエスト内容に応じて最適なAIモデルを選択し、リクエストをルーティングする役割を担います。
実際には両者を組み合わせて運用し、APIゲートウェイがリクエスト管理、AIルーターがモデル選択を担当します。
AIモデルルーティングの主な利用シーン
AIエコシステムの拡大に伴い、AIモデルルーティングは多様なシナリオで活用され、複数モデルの連携による効率化が進んでいます。
AIエージェント:情報検索、分析、コンテンツ生成など複雑なタスクで複数モデルを使い分けます。モデルルーティングにより最適モデルの自動選択が可能です。
AI SaaSプラットフォーム:多様な大規模言語モデルへのアクセスなど、マルチモデルサービスを一元管理し提供します。
AIデータ分析:データ解析では、データパース、論理推論、結果生成など、それぞれに特化したモデルを活用します。
AIルーターインフラの基本アーキテクチャ
AIルーターシステムは通常、以下の構成要素で構成されます。
APIアクセス層:アプリケーションやAIエージェントからのリクエスト受信
ルーティング判断層:リクエスト内容の解析とモデル選定
モデル実行層:複数のモデルプロバイダー(大規模言語モデルなど)への接続
モニタリング・最適化システム:モデルのパフォーマンス・応答速度・コストを監視し、ルーティング戦略を継続的に最適化
この構成により、AIルーターはタスクを効率的に割り振り、柔軟性の高いAIインフラを実現します。
GateRouterのAIルーター分野での役割
マルチモデルAIアプリケーションの拡大に伴い、複数AIモデルを統合管理できるAIルータープラットフォームの需要が高まっています。
一部のAIインフラプロバイダーは、GateRouterのような統合モデルアクセスインターフェースを提供し、複数の大規模言語モデルサービスを一元管理します。
GateRouterは従来のAI APIゲートウェイと異なり、自動化AIアプリケーションに特化し、AIエージェントへのモデルアクセス付与や自動呼び出し、タスク実行をサポートします。さらに、AIエージェント自動決済APIx402プロトコルを統合し、サービス利用時の自動決済も可能です。
まとめ
AIモデルルーティングは、マルチモデルAIアーキテクチャの基盤技術です。複数AIモデル間でタスクを動的に振り分けることで、アプリケーションのパフォーマンス・コスト・応答速度の最適化を実現します。
AIエージェントや自動化AIアプリケーションの普及により、マルチモデルアーキテクチャはAIシステムの主流となりつつあります。AIモデルルーティングは効率化だけでなく、安定性や柔軟性の向上にも大きく貢献します。
この流れの中で、AIルータープラットフォームはAIモデル・開発者・自動化アプリケーションをつなぐ重要なインフラとなっています。
よくある質問
AIモデルルーティングとは?
AIモデルルーティングは、複数AIモデルの中から最適なものを動的に選択し、リクエストを処理する技術です。
AIルーターとLLMルーターの違いは?
LLMルーターは大規模言語モデル専用のルーティングシステムを指し、AIルーターはより幅広い種類のAIモデルを管理します。
なぜAIアプリケーションにマルチモデルアーキテクチャが必要なのですか?
AIモデルごとに能力・コスト・速度が異なるため、マルチモデル構成によってタスクごとに最適なモデルを選べます。
AIモデルルーティングはどのようにコスト削減に寄与しますか?
モデルルーティングにより、単純なタスクは低コストモデル、複雑なタスクは高性能モデルに割り当てることで、全体の運用コストを抑えられます。
共有
内容
ステーブルコインがラテンアメリカの暗号資産購入の40%を獲得し、初めてビットコインを上回った
ドージコインのクジラの活動が6か月ぶりの高水準に到達。24時間で$100K あたり739件の取引が発生
CoinSharesはNasdaq上場以来初の年次報告書でAUM(運用資産)74億ドルを記録
トランプ氏は、イランが合意に関して大きな進展をしたと述べた。現在のパキスタン協議は5月2日に電話で行われた
米上院の暗号法案は5月中旬の審議開始をにらむ、トランプとの関係をめぐる倫理上の争いが今後の道筋を曇らせる


関連記事

ONDOトークン経済モデル:プラットフォームの成長とユーザーエンゲージメントをどのように推進するのか

Raydiumの利用方法:初心者のための取引と流動性提供ガイド

Render、io.net、Akash:DePINハッシュレートネットワークの比較分析

AI分野におけるRenderの申請理由:分散型ハッシュレートが人工知能の発展を支える仕組み

Falcon Financeトークノミクス:FFバリューキャプチャの解説
