Google、精度を損なわずにAIの記憶容量を縮小—しかし、落とし穴がある
Decrypt
In brief
- Google said its TurboQuant algorithm can cut a major AI memory bottleneck by at least sixfold with no accuracy loss during inference.
- Memory stocks including Micron, Western Digital and Seagate fell after the paper circulated.
- The method compresses inference memory, not model weights, and has only been tested in research benchmarks.
Google Research published TurboQuant on Wednesday, a compression algorithm that shrinks a major inference-memory bottleneck by at least 6x while maintaining zero loss in accuracy. The paper is slated for presentation at ICLR 2026, and the reaction online was immediate. Cloudflare CEO Matthew Prince called it Google’s DeepSeek moment. Memory stock prices, including Micron, Western Digital, and Seagate, fell on the same day.
So is it real? Quantization efficiency is a big achievement by itself. But “zero accuracy loss” needs context. TurboQuant targets the KV cache—the chunk of GPU memory that stores everything a language model needs to remember during a conversation. As context windows grow toward millions of tokens, those caches balloon into hundreds of gigabytes per session. That’s the actual bottleneck. Not compute power but raw memory.
Traditional compression methods try to shrink those caches by rounding numbers down—from 32-bit floats to 16, to 8 to 4-bit integers, for example. To better understand it, think of shrinking an image from 4K, to full HD, to 720p and so. It’s easy to tell it’s the same image overall, but there’s more detail in 4K resolution. The catch: they have to store extra “quantization constants” alongside the compressed data to keep the model from going stupid. Those constants add 1 to 2 bits per value, partially eroding the gains. TurboQuant claims it eliminates that overhead entirely. It does this via two sub-algorithms. PolarQuant separates magnitude from direction in vectors, and QJL (Quantized Johnson-Lindenstrauss) takes the tiny residual error left over and reduces it to a single sign bit, positive or negative, with zero stored constants. The result, Google says, is a mathematically unbiased estimator for the attention calculations that drive transformer models. In benchmarks using Gemma and Mistral, TurboQuant matched full-precision performance under 4x compression, including perfect retrieval accuracy on needle-in-haystack tasks up to 104,000 tokens. For context on why those benchmarks matter, expanding a model’s usable context without quality loss has been one of the hardest problems in LLM deployment.
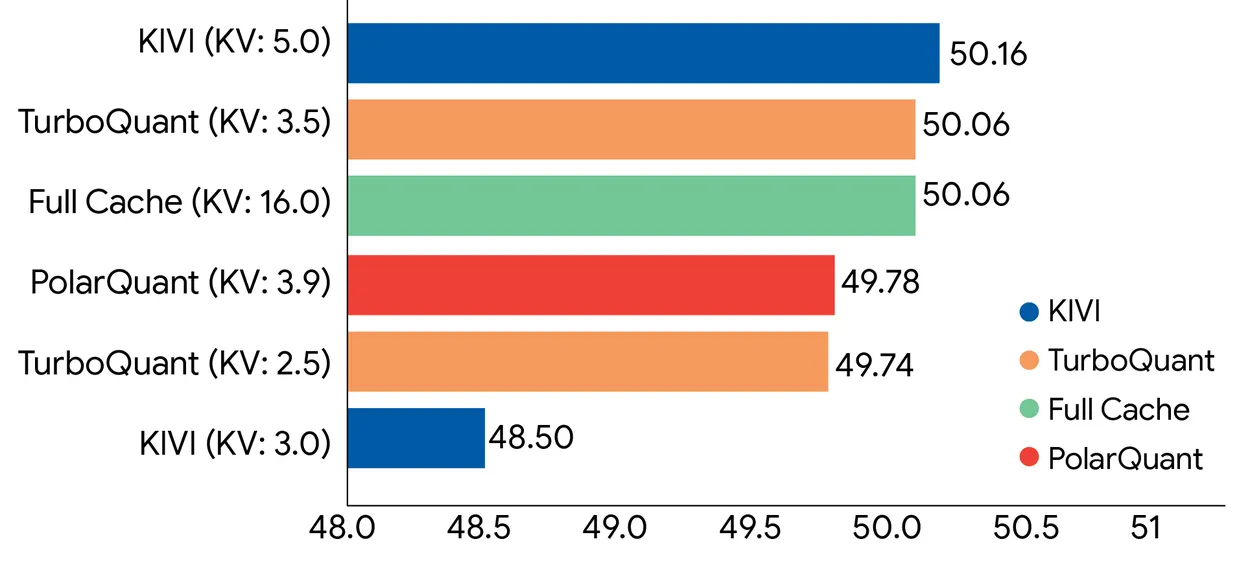
Now, the fine print. “Zero accuracy loss” applies to KV cache compression during inference—not to the model’s weights. Compressing weights is a completely different, harder problem. TurboQuant doesn’t touch those. What it compresses is the temporary memory storing mid-session attention computations, which is more forgiving because that data can theoretically be reconstructed. There’s also the gap between a clean benchmark and a production system serving billions of requests. TurboQuant was tested on open-source models—Gemma, Mistral, Llama—not Google’s own Gemini stack at scale. Unlike DeepSeek’s efficiency gains, which required deep architectural decisions baked in from the start, TurboQuant requires no retraining or fine-tuning and claims negligible runtime overhead. In theory, it drops straight into existing inference pipelines. That’s the part that spooked the memory hardware sector—because if it works in production, every major AI lab runs leaner on the same GPUs they already own. The paper goes to ICLR 2026. Until it ships in production, the “zero loss” headline stays in the lab.
免責事項:このページの情報は第三者から提供される場合があり、Gateの見解または意見を代表するものではありません。このページに表示される内容は参考情報のみであり、いかなる金融、投資、または法律上の助言を構成するものではありません。Gateは情報の正確性または完全性を保証せず、当該情報の利用に起因するいかなる損失についても責任を負いません。仮想資産への投資は高いリスクを伴い、大きな価格変動の影響を受けます。投資元本の全額を失う可能性があります。関連するリスクを十分に理解したうえで、ご自身の財務状況およびリスク許容度に基づき慎重に判断してください。詳細は免責事項をご参照ください。
コメント
0/400
コメントなし