51,2万行 de código, 1906 ficheiros, 59,8 MB de source map. Na madrugada de 31 de março, Chaofan Shou, da Solayer Labs, descobriu que o produto flagship da Anthropic, o Claude Code, expunha o código-fonte completo num repositório público npm. Em poucas horas, o código foi replicado no GitHub, e o número de forks ultrapassou 41.000.
Este não é o primeiro erro da Anthropic. Quando o Claude Code foi publicado pela primeira vez, em fevereiro de 2025, ocorreu uma fuga do mesmo source map. Desta vez, a versão era a v2.1.88; a causa da fuga era a mesma: a ferramenta de build Bun gera source map por predefinição, e o ficheiro ficou omisso em .npmignore.
A maior parte das notícias está a inventariar os ovos de Páscoa na fuga, como um sistema de animal virtual de estimação e um “modo de infiltrado” que permite ao Claude submeter código de forma anónima a projetos open source. Mas a questão verdadeiramente digna de desmontar é: por que é que o mesmo modelo do Claude, tanto na versão para a web como no Claude Code, se comporta de forma tão diferente? Afinal, o que é que 51,2 mil linhas de código estão a fazer?
O modelo é apenas a ponta do iceberg
A resposta está escondida na estrutura do código. De acordo com uma análise de engenharia inversa do código-fonte vazado pela comunidade do GitHub, entre os 512.000 linhas de TypeScript, apenas cerca de 8000 linhas de código são diretamente responsáveis por chamar a interface do modelo de IA, o que corresponde a 1,6% do total.
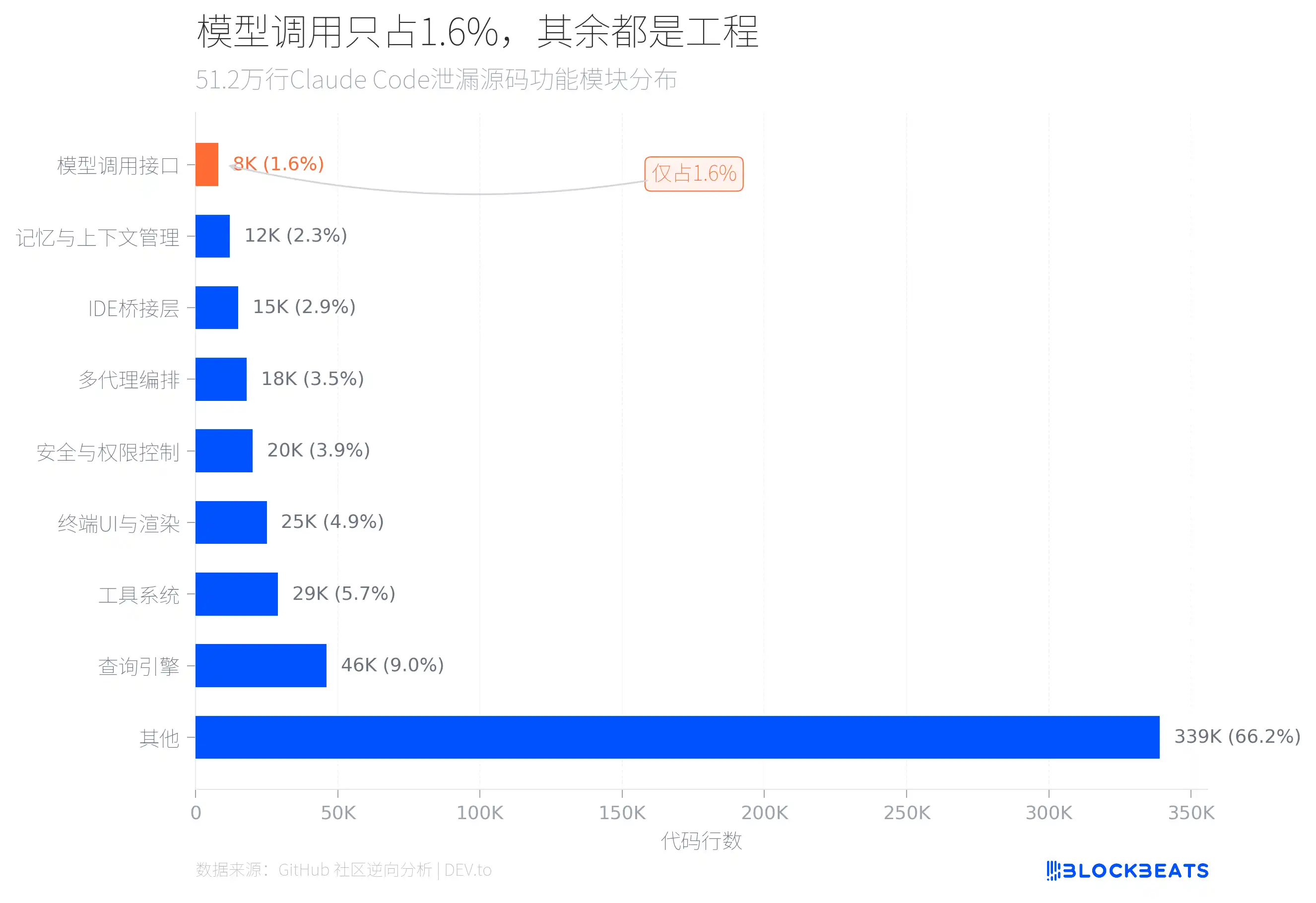
O que é que os restantes 98,4% estão a fazer? Os dois maiores módulos são o motor de query engine (46.000 linhas) e o sistema de ferramentas (29.000 linhas). O motor de query engine trata de chamadas à LLM API, output em streaming, orquestração de cache e gestão de conversas de múltiplas rondas. O sistema de ferramentas define cerca de 40 ferramentas embutidas e 50 comandos com barra (/), formando uma arquitetura tipo plug-in; cada ferramenta tem controlos de permissões independentes.
Além disso, há também 25.000 linhas de código de renderização de UI do terminal (uma, chamada print.ts, tem até 5594 linhas, e uma função individual atravessa 3167 linhas), 20.000 linhas de segurança e controlo de permissões (incluindo 23 verificações de segurança Bash numeradas e 18 comandos embutidos de Zsh bloqueados), e 18.000 linhas de um sistema de orquestração de múltiplos agentes.
O investigador de pesquisa em machine learning, Sebastian Raschka, após analisar o código vazado, apontou que a razão pela qual o Claude Code é mais forte do que a versão para a web com o mesmo modelo não está no próprio modelo, mas sim no “andaime” de software construído em torno do modelo: carregamento de contexto do repositório, escalonamento de ferramentas dedicadas, estratégias de cache e colaboração entre subagentes. Ele chegou mesmo a considerar que, se a mesma arquitetura de engenharia fosse aplicada a outros modelos, como o DeepSeek ou Kimi, também se obteria um aumento de desempenho em programação bastante próximo.
Uma comparação intuitiva ajuda a compreender esta diferença. Tu introduzes uma pergunta no ChatGPT ou no Claude versão web; o modelo processa e devolve a resposta, e a conversa termina sem deixar nada para trás. Mas o Claude Code faz totalmente o contrário: ao iniciar, lê primeiro os ficheiros do teu projeto, compreende a estrutura da tua base de código, e memoriza preferências como “não mockar a base de dados nos testes” que disseste na conversa anterior. Consegue executar comandos diretamente no teu terminal, editar ficheiros e correr testes; quando lida com tarefas complexas, divide-as em várias sub-tarefas e atribui-as a diferentes subagentes para processamento em paralelo. Por outras palavras, a IA na versão web é uma janela de perguntas e respostas; o Claude Code é um colaborador que vive no teu computador.
Alguém comparou esta arquitetura a um sistema operativo: 42 ferramentas embutidas equivalem a chamadas de sistema, o sistema de permissões equivale à gestão de utilizadores, o protocolo MCP corresponde a drivers de dispositivo, e a orquestração de subagentes equivale ao escalonamento de processos. Cada ferramenta, aquando do lançamento, é por predefinição marcada como “insegura, com permissão de escrita”, a menos que o programador declare proactivamente que é segura. O instrumento para editar ficheiros obriga a verificar se tu leste primeiro esse ficheiro; se não o tiveres lido, não te deixa modificá-lo. Isto não é simplesmente um “plug-in” de um chatbot com algumas ferramentas; é um ambiente de execução com o LLM como núcleo e com mecanismos de segurança completos.
Isto significa uma coisa: a barreira competitiva dos produtos de IA pode não estar na camada do modelo, mas sim na camada de engenharia.
Sempre que a cache falha, o custo multiplica por 10
No código vazado existe um ficheiro chamado promptCacheBreakDetection.ts, que rastreia 14 vetores possíveis que podem causar invalidação do cache de prompts. Porque é que os engenheiros da Anthropic gastariam tanta energia para evitar que a cache “quebre”?
Basta olhar para a tabela oficial de preços da Anthropic para perceber. Por exemplo, no caso do Claude Opus 4.6, o preço do input padrão é 5 dólares por cada milhão de tokens; mas se houver acerto de cache, o preço de leitura é apenas 0,5 dólares, ou seja, 90% mais barato. Pelo contrário: cada vez que a cache falha (não acerta), o custo de inferência precisa de multiplicar por 10.
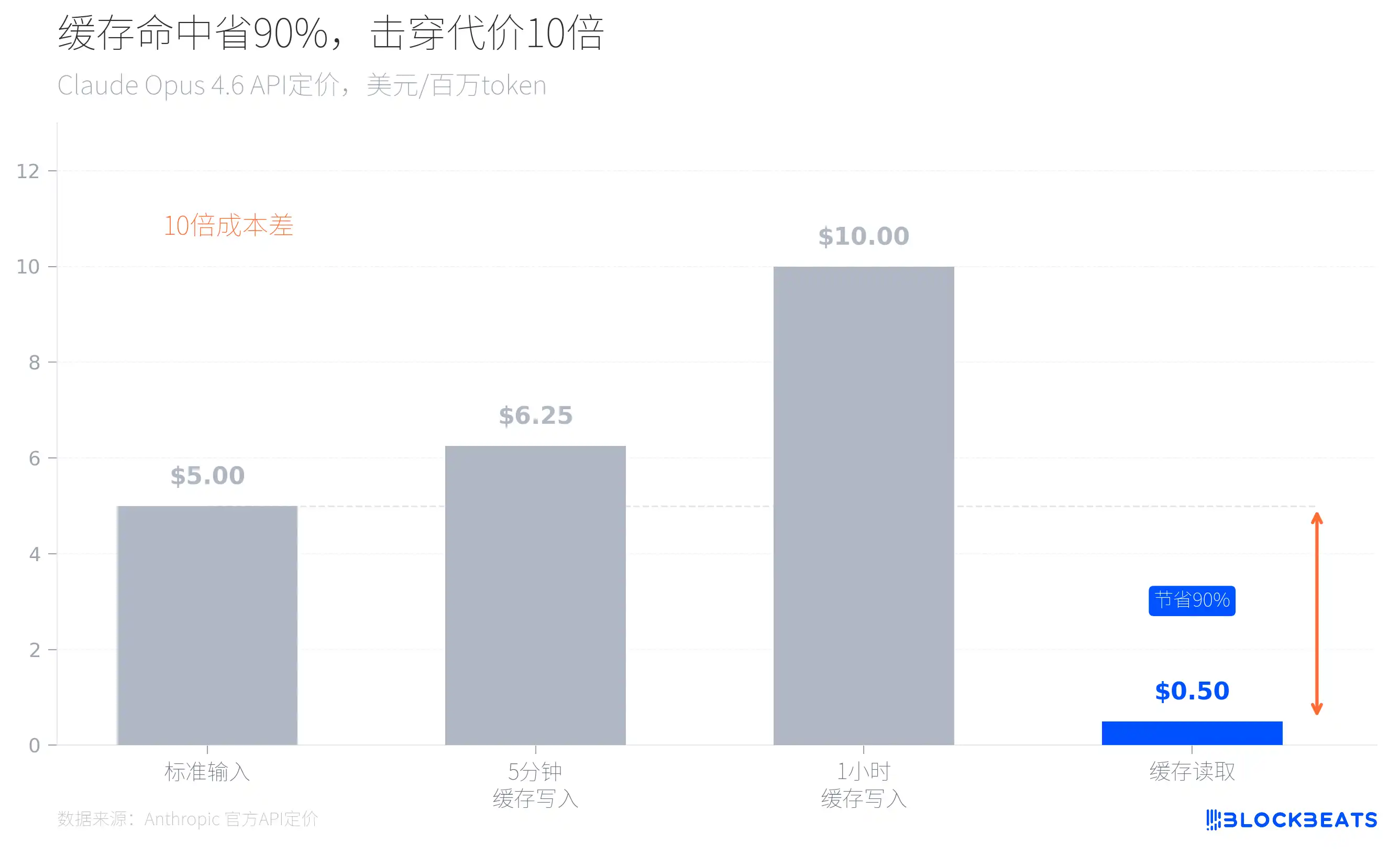
Isto explica as muitas decisões de arquitetura que parecem “exageradamente desenhadas” no código vazado. Quando o Claude Code inicia, carrega a branch git atual, os registos de commits mais recentes e o ficheiro CLAUDE.md como contexto; esses conteúdos estáticos são armazenados em cache globalmente, separados por marcadores de fronteira para o conteúdo dinâmico, garantindo que em cada conversa não se faça novamente o processamento de contextos já existentes. O código inclui também um mecanismo chamado sticky latches, que impede que a mudança de modo destrua a cache já estabelecida. Os subagentes foram desenhados para reutilizar a cache do processo pai, em vez de reestabelecer as suas próprias janelas de contexto.
Há um detalhe aqui que vale a pena aprofundar. Quem já usou ferramentas de programação com IA sabe: quanto mais longa a conversa, mais lenta a resposta da IA, porque em cada ronda é necessário reenviar para o modelo todo o histórico anterior. A prática comum é apagar mensagens antigas para libertar espaço, mas o problema é que apagar qualquer mensagem quebra a continuidade da cache, levando a que seja necessário reprocessar todo o histórico da conversa — e isso faz disparar tanto a latência como os custos.
No código vazado existe um mecanismo chamado cache_edits: em vez de não apagar de verdade as mensagens, marca-se as mensagens antigas com um “skip” no nível da API. O modelo já não vê essas mensagens, mas a continuidade da cache não é destruída. Isto significa que numa conversa longa que dura algumas horas, depois de limpar centenas de mensagens antigas, a velocidade da próxima resposta fica quase igual à da primeira. Para um utilizador comum, esta é a resposta “de base” para a questão de por que é que o Claude Code consegue suportar conversas infinitamente longas sem ficar mais lento.
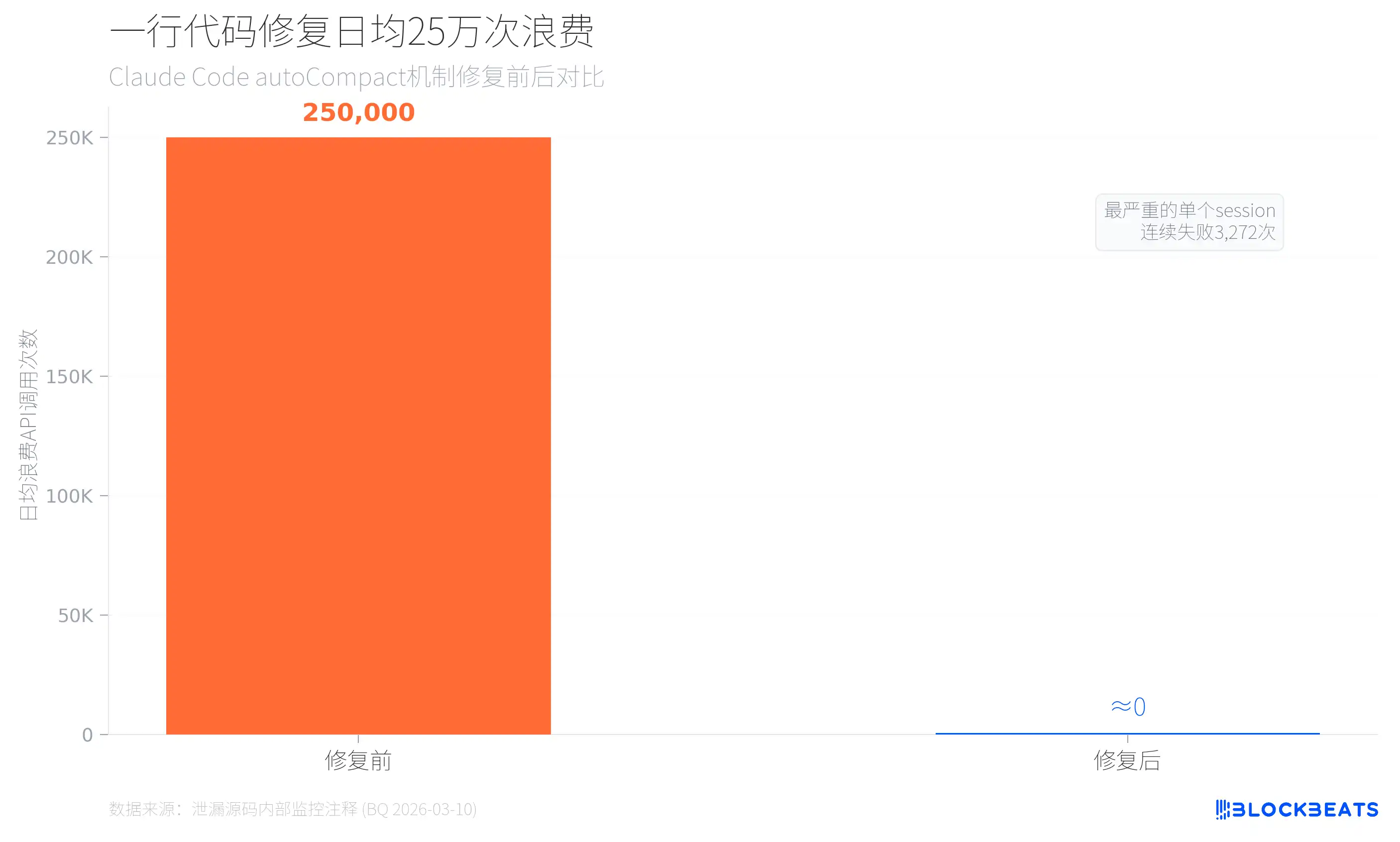
De acordo com dados internos de monitorização da fuga (provenientes de comentários de código de autoCompact.ts, com data assinalada a 10 de março de 2026), antes de serem introduzidos limites de falha de compressão automática, o Claude Code desperdiçava cerca de 250.000 chamadas de API por dia. Houve 1279 sessions de utilizadores com 50 ou mais falhas consecutivas de compressão; o caso mais grave teve 3272 falhas consecutivas num único session. A correção foi apenas adicionar uma única linha de limitação: MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES = 3.
Assim, para produtos de IA, o custo de inferência do modelo talvez não seja a camada mais cara; falhas na gestão de cache é que podem ser.
44 interruptores, apontam para a mesma direção
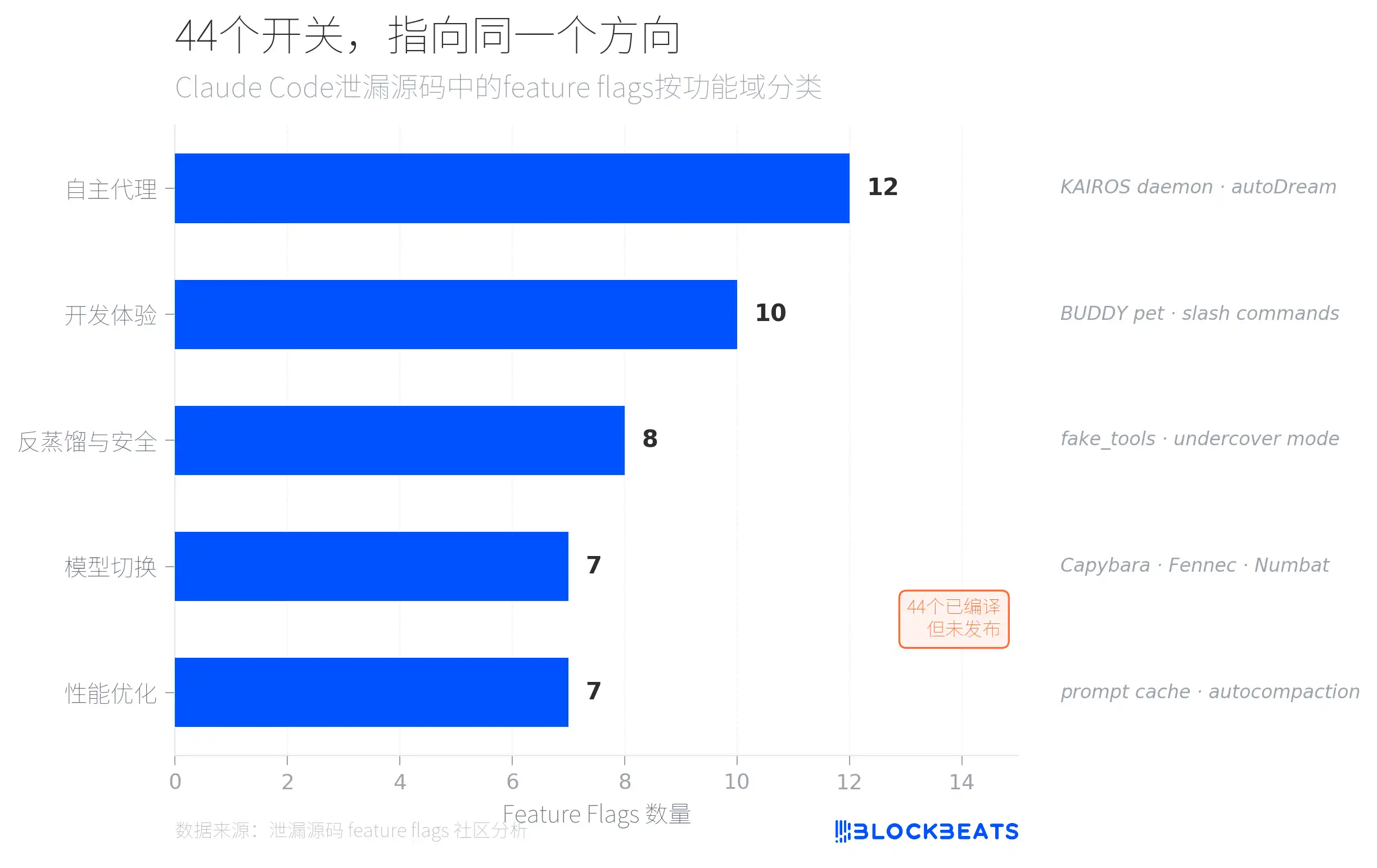
No código vazado há 44 feature flags — switches de funcionalidade já compilados, apenas sem terem sido lançados ao público. De acordo com análises da comunidade, estas flags se dividem em cinco categorias por domínio funcional; a mais densa é a classe de “agentes autónomos” (12), apontando para um sistema chamado KAIROS.
O KAIROS é referenciado no código-fonte mais de 150 vezes; é um modo de processo daemon em segundo plano permanente. O Claude Code já não é apenas uma ferramenta que responde quando tu a invocas manualmente: é um agente que corre sempre em segundo plano, observando continuamente, registando e agindo proactivamente no momento certo. O pressuposto é que não interrompe o utilizador; qualquer operação que possa bloquear o utilizador por mais de 15 segundos é adiada para execução.
O KAIROS também tem perceção de foco do terminal. O código inclui um campo terminalFocus que deteta em tempo real se o utilizador está a ver a janela do terminal. Quando alternas para o browser ou para outra aplicação, o agente determina que “tu não estás” e muda para modo autónomo, executando tarefas de forma proactiva e submetendo código diretamente, sem esperar pela tua confirmação. Quando voltas ao terminal, o agente regressa imediatamente ao modo de colaboração: primeiro dá conta do que fez e depois pede a tua opinião. O grau de autonomia não é fixo — flutua em tempo real com a tua atenção. Isto resolve um constrangimento de longa data das ferramentas de IA: uma IA totalmente autónoma não inspira confiança; uma IA totalmente passiva tem eficiência demasiado baixa. A escolha do KAIROS é fazer a proatividade da IA ajustar-se dinamicamente à atenção do utilizador: quando tu o vês, ele fica quieto; quando tu te afastas, ele faz o trabalho sozinho.
Outro subsistema do KAIROS chama-se autoDream: sempre que se acumulam 5 sessões ou quando passam 24 horas, o agente inicia em segundo plano um processo de “reflexão”, em quatro passos. Primeiro, analisa memórias existentes para perceber o que já domina. Depois, extrai novos conhecimentos dos registos de conversa. Em seguida, funde o novo e o antigo conhecimento, corrigindo contradições e removendo duplicações. Por fim, reduz os índices e apaga entradas ultrapassadas. Este desenho é inspirado na teoria de consolidação da memória da ciência cognitiva. Enquanto as pessoas dormem, elas organizam memórias do dia; quando o utilizador se afasta, o KAIROS organiza o contexto do projeto. Para um utilizador comum, isto significa que quanto mais tempo usas o Claude Code, mais precisa se torna a compreensão do teu projeto — não é apenas “memorizar o que tu disseste”.
A segunda maior categoria são “anti-evaporação e segurança” (8 flags). A mais digna de atenção é o mecanismo fake_tools: quando quatro condições são satisfeitas em simultâneo (flag de compilação ativada, entrada CLI ativada, utilização de API de primeira parte, e o remote switch do GrowthBook definido como true), o Claude Code injeta definições falsas de ferramentas nos pedidos à API com o objetivo de contaminar conjuntos de dados que possam estar a gravar fluxos de API e a serem usados para treinar modelos de concorrentes. Trata-se de uma nova forma de defesa numa corrida armamentista de IA: não é impedir-te de copiar; é fazer com que copies coisas erradas.
Além disso, também aparece no código um código-nome de modelo Capybara (dividido em três níveis: versão standard, versão fast e versão com janela de contexto para um milhão). A comunidade especula amplamente que seja o código interno da série Claude 5.
Ovos de Páscoa: numa pilha de 512.000 linhas de código, há um animal eletrónico de estimação
Entre todas as arquiteturas sérias e os mecanismos de segurança, os engenheiros da Anthropic construíram silenciosamente um sistema completo de animal virtual de estimação, com o código interno BUDDY.
De acordo com o código vazado e a análise da comunidade, o BUDDY é um animal de estimação terminal com estilo “parcialmente realista” (拟物化): aparece no lado do campo de entrada do utilizador em forma de caixas-bolha ASCII. Tem 18 espécies (incluindo capivara-paquiderme? [água], tritões? [espaçador], cogumelos, fantasmas, dragões, e uma série de criaturas originais como Pebblecrab, Dustbunny e Mossfrog), classificadas em cinco níveis de raridade: comum (60%), raro (25%), raro (10%), épico (4%) e lendário (1%). Cada espécie também tem “variante brilhante”; a mais rara, Shiny Legendary Nebulynx, tem apenas 1 em 10.000 de probabilidade de aparecer.
Cada BUDDY tem cinco atributos: DEBUGGING (depuração), PATIENCE (paciência), CHAOS (caos), WISDOM (sabedoria) e SNARK (sarcasmo). Também usam chapéus; as opções incluem coroa, cartola, chapéu com hélice, auréola, chapéu de feiticeiro, e até um mini pato. O valor hash do ID do utilizador determina que animal vais “incubar”. O Claude vai gerar um nome e uma personalidade para ele.
De acordo com o plano de lançamento do vazamento, o BUDDY estava originalmente previsto para iniciar testes internos entre 1 e 7 de abril; o lançamento oficial seria em maio, começando pelos funcionários internos da Anthropic.
512.000 linhas de código, 98,4% a fazer engenharia hardcore, mas por fim alguém gastou tempo a fazer um escorpião/cefalópode eletrónico que usa um chapéu com hélice. Talvez seja esta mesmo a linha de código mais humana na fuga.
Clique para saber mais sobre a contratação do律动BlockBeats (BlockBeats)
Bem-vindo a juntar-se à comunidade oficial do律动 BlockBeats:
Grupo de subscrição no Telegram: https://t.me/theblockbeats
Grupo no Telegram: https://t.me/BlockBeats_App
Conta oficial no Twitter: https://twitter.com/BlockBeatsAsia

