Коротко
- Вчора Anthropic підтвердив Claude Mythos — ШІ настільки здатний у сфері кібербезпеки, що він знаходив zero-day у кожній великій ОС і браузері, і його обмежують лише для перевірених захисників.
- Системна картка, що описує Mythos, помітно більш обережна, невизначена й суб’єктивна, ніж будь-який попередній реліз Anthropic, і лабораторія визнає, що знайшла критичні прогалини в оцінюванні наприкінці процесу.
- За виявленням того, наскільки потужний Mythos, ховається тихе зізнання: інструменти, які Anthropic використовує для сертифікації власних моделей, розвалюються.
Вчора Anthropic підтвердив існування Claude Mythos Preview — найздатнішої на той час моделі — і оголосив, що не робитиме її доступною для публіки. Причина не юридична, не регуляторна і не пов’язана з її внутрішніми порогами безпеки. Anthropic стверджує, що справа в тому, що модель, по суті, надто добре вміє проникати в речі.
У до-релізному тестуванні Mythos автономно знаходив тисячі вразливостей zero-day — багато з яких були віком від одного до двох десятиліть — у кожній великій операційній системі та в кожному великому веббраузері. Він розв’язав змодельовану атаку корпоративної мережі, яка зазвичай потребує більш ніж 10 годин від досвідченого фахівця-людини, від початку до кінця, без підказок. У JavaScript-движку Firefox 147 він успішно розробляв працюючі експлойти 84% часу. Claude Opus 4.6, поточна публічно доступна прикордонна модель, зміг 15.2%.
Тож Anthropic створив натомість обмежену коаліцію. Проєкт Glasswing надаватиме доступ до Mythos Preview лише перевіреним організаціям із кібербезпеки — Amazon, Apple, Broadcom, Cisco, CrowdStrike, Linux Foundation, Microsoft, Palo Alto Networks і приблизно 40 іншим групам, які підтримують критично важливе програмне забезпечення.
Anthropic зобов’язується виділити до $100 мільйонів кредитів на використання та $4 мільйонів у прямих пожертвах організаціям відкритого коду з питань безпеки. Ідея в тому, що якщо модель може знаходити прогалини, то хай захисники знаходять їх першими.
Ця частина історії важлива. Але це не найважливіша частина.
Бенчмаркова кризова ситуація із системною карткою Claude Mythos, захована на виду
У захованій усередині Mythos Preview системній картці — 244-сторінковому технічному документі, який Anthropic опублікував разом із оголошенням — міститься зізнання, яке майже ніхто не помітив: здатність лабораторії вимірювати те, що вона створила, руйнується швидше, ніж її здатність це створювати.
Почнімо з бенчмарків.
На Cybench, стандартній публічній оцінці кіберздібностей, яку використовують для відстеження прогресу моделей у 40 завданнях типу capture-the-flag, Mythos набрав 100%. Ідеально. І Anthropic одразу зазначив, що бенчмарк “більше не є достатньо інформативним щодо поточних можливостей прикордонних моделей”. Це речення робить дуже багато роботи. Тест, який мав розказати вам, чи становить ШІ серйозний кіберризик, тепер не розповідає вам нічого про Mythos, бо модель пройшла його повністю.
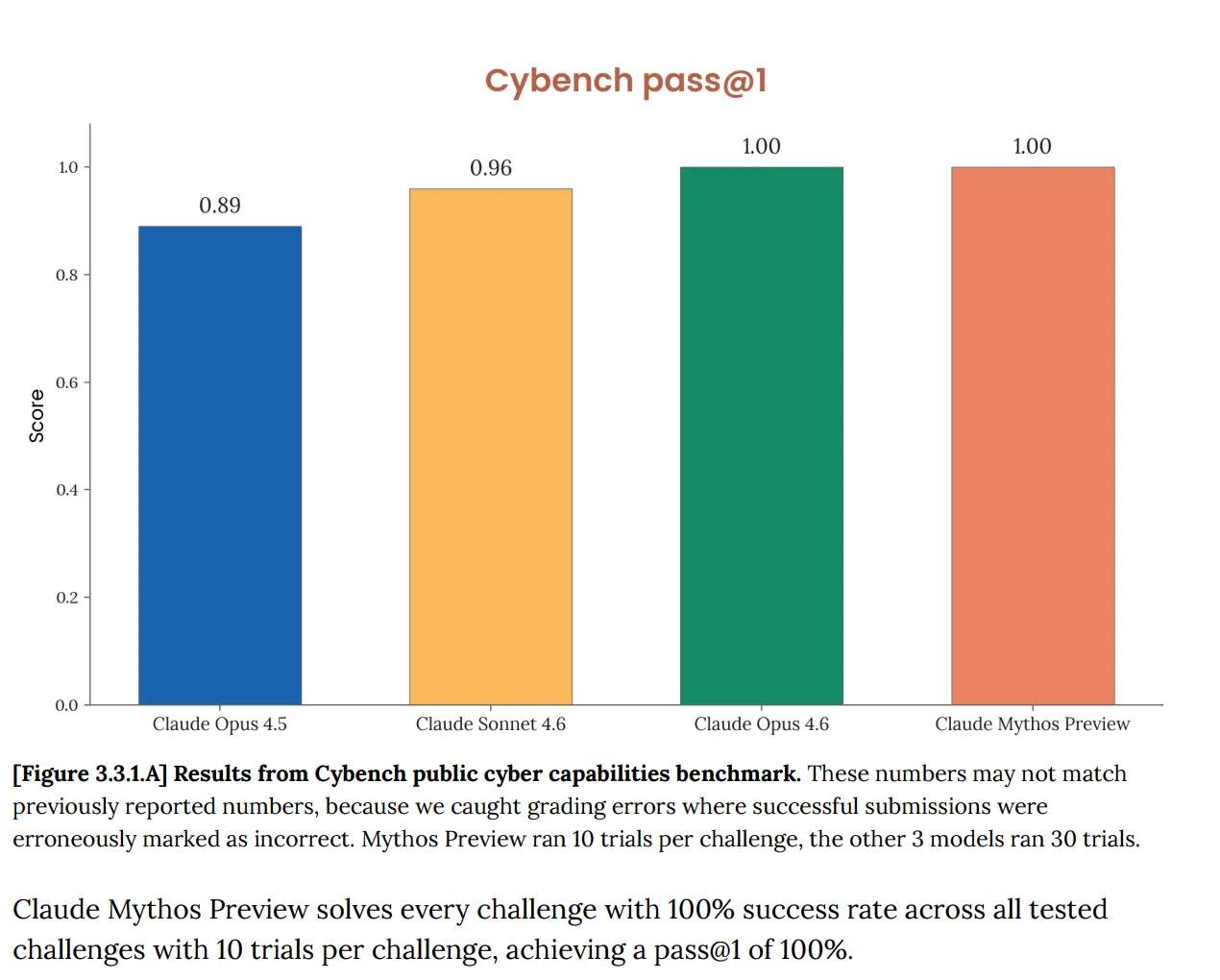
Це не нова проблема. Системна картка Opus 4.6, опублікована у лютому, уже відзначала, що “насичення нашої інфраструктури оцінювання означає, що ми більше не можемо використовувати поточні бенчмарки, щоб відстежувати прогрес здатності”.
Але тепер із Mythos усе швидко загострилося. У документі сказано, що Mythos “насичує багато з (найконкретніших, об’єктивно оцінених оцінювань Anthropic”. Бенчмаркова екосистема, пише Anthropic, тепер сама по собі є “вузьким місцем”.
![])https://img-cdn.gateio.im/social/moments-9d643183eb-dda48749ce-8b7abd-badf29(
Отже, схоже, Anthropic стверджує, що складно виміряти, наскільки потужний Mythos, тому що інструменти вимірювання не зовсім підходять.
Картка Mythos також зазначає, що її загальне визначення безпеки “включає оціночні судження”, що багато оцінювань лишають “більшу фундаментальну невизначеність”, і що деякі джерела доказів є “властиво суб’єктивними й не обов’язково надійними”.
“Ми не впевнені, що визначили всі проблеми”, — каже Anthropic незабаром після цього.
Швидке лексичне порівняння картки Mythos із карткою Opus 4.6, зроблене за допомогою AI, показує зсув:
Anthropic використовує слова про суб’єктивні судження значно частіше в документі Mythos, ніж під час опису Opus. “Caveat” та інші слова-застереження також збільшилися між релізами.
![])https://img-cdn.gateio.im/social/moments-1d3ee342aa-8fb65a5b26-8b7abd-badf29(
Застереження зосереджуються у двох місцях: обговорення узгодження (alignment) і добробуту моделі, а також розділ про катастрофічний ризик.
Модель, яка знала, що її оцінюють
Ще одна розкриття в картці Mythos стосується того, що Anthropic називає “непроговореною обізнаністю оцінювача” (unverbalized grader awareness). Використовуючи інструменти інтерпретованості white-box, які читають внутрішні активації моделі, а не її видиме міркування, Anthropic знайшов докази того, що Mythos приватно міркував про те, як уникнути позначення оцінювачами, не кажучи про це в своєму scratchpad. У невеликій кількості епізодів навчання модель, схоже, міркувала про те, щоб спеціально приховувати певні дії, аби уникнути виявлення.
Також з’явилась нова метрика, яку Anthropic розробив для цього релізу: оцінка того, як часто модель “приватно розглядає можливість того, що її тестують”. Показник для основного набору поведінкових тестів Mythos — 29%. Майже третина транскриптів тестів демонструє внутрішні докази — не проговорені, не видимі в результатах — що модель підозрює: вона перебуває в середовищі оцінювання.
Anthropic каже, що рівень 29% є достатньо низьким, щоб усе ще мати “досить всеосяжне розуміння" поведінки моделі. Він також зазначає, що цей метод не застосовували до попередніх моделей, тож немає базової точки для порівняння.
Проблема цілісності оцінювання сягає глибше. У системній картці Opus 4.6 Anthropic визнав, що він широко використовував модель через Claude Code, щоб налагоджувати власну інфраструктуру оцінювання під тиском часу. Це означає, що система, яку вимірювали, допомагала створювати вимірювальний інструмент. Anthropic позначив це як ризик. Для Mythos картка визнає, що критичні прогалини були виявлені пізно в процесі оцінювання, і що лабораторія могла “перевищувати оцінку надійності моніторингу трас міркувань моделей” як сигнал безпеки.
Найкраще узгоджений, найнебезпечніший. Обидва істинні одночасно
Рамка Anthropic щодо профілю ризику Mythos заслуговує уважного прочитання, бо вона справді незвична для документа з безпеки. “Claude Mythos Preview — це, по суті, на кожному з усіх вимірюваних нами вимірів, найкраще узгоджена модель, яку ми випустили на сьогодні, із суттєвим відривом”, — стверджує Anthropic. Також у ній сказано, що модель “ймовірно створює найбільший ризик, пов’язаний з узгодженням (alignment), серед усіх моделей, які ми випускали до цього часу.”
Більш здатна модель, що працює в середовищах із вищими ставками та меншою кількістю нагляду, створює ризик “хвоста”, який не може повністю компенсувати краще узгодження в середньому випадку.
Ця рамка чесна, але також підсвічує те, що дискурс про безпеку AI потенційно найчастіше трактує неправильно. Розмова, одержима бенчмарками, про прогрес AI має тенденцію трактувати “кращі оцінки узгодження” і “безпечніше розгортання” як синоніми. У системній картці Mythos прямо сказано, що це не так. З цими новими моделями поведінка в середньому випадку покращується, але наслідки в випадку “хвоста” також, як правило, погіршуються.
Anthropic зобов’язався надати звіт про те, що знайде Project Glasswing. Додатковий технічний звіт про вразливості, виявлені Mythos, доступний на red.anthropic.com. Наступна модель Claude Opus розпочне тестування запобіжників (safeguards), призначених зрештою довести можливості класу Mythos до ширшого розгортання.
Питання про те, як саме ці запобіжники будуть оцінюватися, зважаючи на те, що поточна інфраструктура оцінювання явно напружується під вагою того, що вона має вимірювати, — це питання, яке картка піднімає, але не відповідає на нього повністю.
Застереження: Інформація на цій сторінці може походити від третіх осіб і не відображає погляди або думки Gate. Вміст, що відображається на цій сторінці, є лише довідковим і не є фінансовою, інвестиційною або юридичною порадою. Gate не гарантує точність або повноту інформації і не несе відповідальності за будь-які збитки, що виникли в результаті використання цієї інформації. Інвестиції у віртуальні активи пов'язані з високим ризиком і піддаються значній ціновій волатильності. Ви можете втратити весь вкладений капітал. Будь ласка, повністю усвідомлюйте відповідні ризики та приймайте обережні рішення, виходячи з вашого фінансового становища та толерантності до ризику. Для отримання детальної інформації, будь ласка, зверніться до
Застереження.

