微软让 GPT 和 Claude 协同工作——而结果击败了现有的所有 AI 研究工具
Decrypt
简要概述
- Microsoft 发布了两种不同模式,将 GPT 和 Claude 配对以提高 AI 研究的质量。
- Critique 让模型协作,而 Council 则让它们并行工作;随后由第三位评审找出差异。
- 这种双模型工作流能够修复幻觉、较弱的引用以及与单一模型 AI 研究相关的其他问题。
今年,深度研究型 AI 已成为科技领域最激烈的军备竞赛之一。Google 在 2024 年 12 月为 Gemini 公布了研究代理,OpenAI 在 2025 年 2 月发布了自己的研究代理,xAI 随后紧跟,Perplexity 进一步加码,而 Anthropic 的 Claude 在去年 4 月开始推出其代理,并在专业人士中建立起忠实用户群——这些专业人士需要详尽且带引用的回答。 每家公司都在试图说服你:他们的单一 AI 模型才是房间里最聪明的研究者。Microsoft 刚刚说:为什么要选一个? 该公司在周一宣布了 Copilot 的 Researcher 工具两项新功能——名为 Critique 和 Council——它们让 OpenAI 的 GPT 与 Anthropic 的 Claude 依次投入到同一项研究任务中。根据 Microsoft 在针对行业基准的测试结果来看,其得分高于测试中包含的所有系统,包括来自顶级 AI 公司的模型。
在 M365 Copilot 中推出 Critique:一种新的多模型深度研究系统。
你可以将多个模型一起使用,以生成最优的响应和报告。pic.twitter.com/m4RlQmCKzs
— Satya Nadella (@satyanadella) March 30, 2026
“Critique 是一种新的多模型深度研究系统,旨在处理复杂研究任务。它将生成与评估分离,并利用来自 Frontier labs 的一组模型,包括 Anthropic 和 OpenAI,”Microsoft 解释道。“一 个模型负责生成阶段:规划任务、迭代检索,并产出初稿;而第二个模型则聚焦审阅与完善,在最终报告生成之前充当专家评审。” 下面是 Critique 旨在修复的核心问题:如今每一种 AI 研究工具都以相同的方式运作。你提出一个问题,一个模型负责规划搜索、搜罗来源、撰写报告,然后把它交还给你。这个单一模型把所有事情都做了,没有人去检查它的工作。 这可能会导致一些幻觉悄悄混入、引用中出现错误、虚假或不准确的说法等问题。
Critique 将这种工作流拆成两部分。GPT 负责第一个阶段——它规划研究、提取来源并撰写初稿。随后 Claude 作为严格的编辑介入,审阅报告的事实准确性、引用质量,以及答案是否真正回应了所提问的问题。只有在这一轮审阅之后,最终报告才会交付给用户。Microsoft 表示,这些角色最终也可以反向运行——由 Claude 起草、由 GPT 进行质询——不过目前仍然是 GPT 先行。
在 DRACO 基准测试中——这一标准化测试覆盖 10 个领域的 100 项复杂研究任务,包括医学、法律和技术——搭载 Critique 的 Copilot 得分为 57.4,而仅由 Anthropic 的 Claude Opus 单独达到 42.7。Microsoft 的组合系统将下一个最佳结果提升了将近 14%。
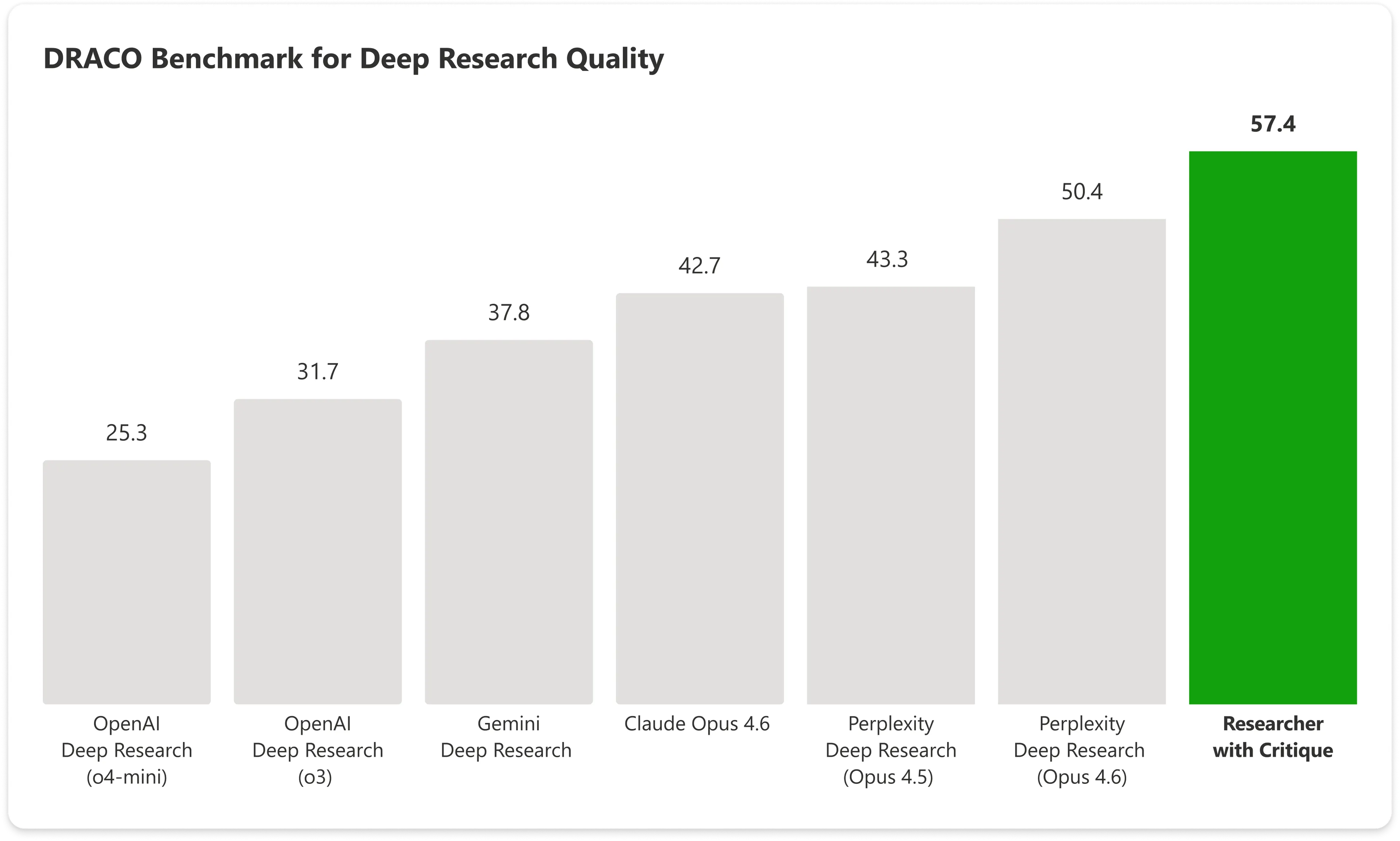
图片:Microsoft
最大的提升出现在分析覆盖范围和呈现质量方面,同时事实准确性也出现了显著改善。
第二项功能 Council 采取了针对同一问题的另一种思路。Council 并不让一个模型去审核另一个模型的工作,而是让 GPT 和 Claude 同时 运行,并将它们的完整报告并排展示。随后,一个第三个“评审”模型读取两份报告,并撰写摘要,说明两 个 AI 在哪些地方达成一致、在哪些地方出现分歧,以及每一个各自捕捉到、而另一个未能发现的独特角度。直到现在,人工对比 AI 研究工具一直是用户需要自行完成的事情。
在 Critique 中,这些模型本质上是彼此 协作;而在 Council 中,模型之间是 竞争。
Critique 是 Researcher 中的默认体验,而 Council 则需要你从选择器里选中“Model Council”来启用并排模式。当前,这两项功能都对参与 Microsoft 的 Frontier 计划的用户开放——这是 Copilot 最新能力的早期访问渠道。使用 Microsoft 365 Copilot 许可证($30/用户/月)是必须的,但用户也需要加入 Frontier 才能访问这些功能。
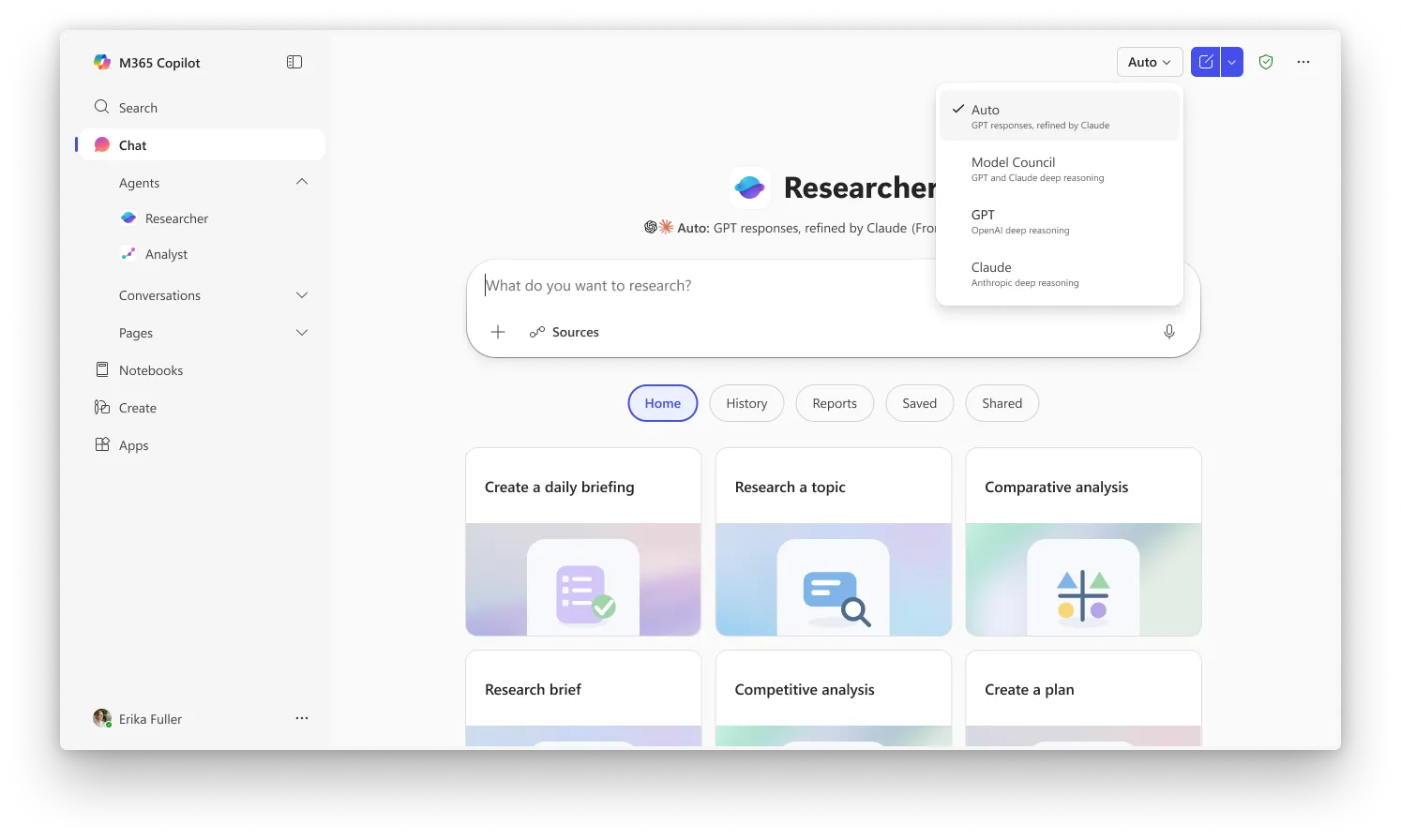
图片:Microsoft
OpenAI 和 Microsoft 有一项多亿美元的合作伙伴关系,但 Microsoft 的押注是:不会有任何一个单一模型长期保持领先;真正的价值在于编排层——它会把任务路由到最适合的任意模型组合。
免责声明:本页面信息可能来自第三方,不代表 Gate 的观点或意见。页面显示的内容仅供参考,不构成任何财务、投资或法律建议。Gate 对信息的准确性、完整性不作保证,对因使用本信息而产生的任何损失不承担责任。虚拟资产投资属高风险行为,价格波动剧烈,您可能损失全部投资本金。请充分了解相关风险,并根据自身财务状况和风险承受能力谨慎决策。具体内容详见声明。
评论
0/400
暂无评论