Le développement rapide des modèles d’intelligence artificielle stimule une forte croissance de la demande mondiale de GPU. À mesure que les grands modèles de langage (LLM), les Agents IA et les applications d’automatisation prennent de l’ampleur, les plateformes cloud d’IA centralisées traditionnelles sont confrontées à des coûts élevés, une concentration des ressources et des difficultés de scalabilité. Dans ce contexte, les réseaux GPU décentralisés s’imposent comme un axe majeur pour l’infrastructure Web3 IA.
Dolphin Network est un réseau d’inférence IA conçu pour répondre à cette évolution. Son objectif principal est d’agréger des ressources GPU réparties à l’échelle mondiale dans une infrastructure IA ouverte et de coordonner développeurs, nœuds GPU et réseau grâce au mécanisme d’incitation POD.
Quelle est la structure de base du Dolphin Network ?
L’architecture fondamentale du Dolphin Network comprend trois éléments : les demandeurs d’inférence IA, le réseau de nœuds GPU et un mécanisme de vérification et de coordination.
Les développeurs ou les applications soumettent des requêtes d’inférence IA — génération de texte, discussion, appel de modèle ou tâches d’Agent IA — au réseau. Le système attribue dynamiquement ces requêtes aux nœuds adaptés selon le statut des nœuds GPU, les besoins des tâches et la disponibilité des ressources.
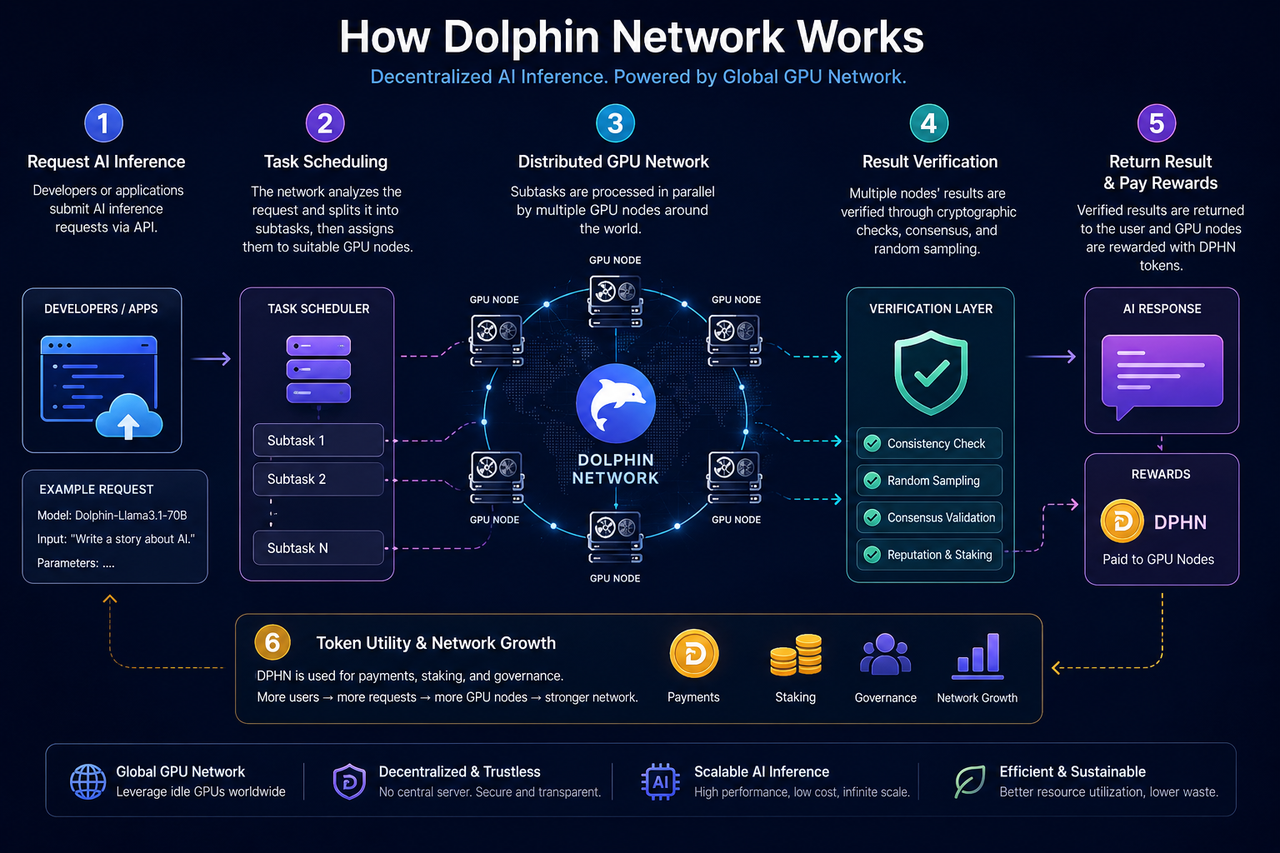
Les nœuds GPU sont fournis par des utilisateurs du monde entier. Les participants peuvent intégrer le réseau avec des GPU inutilisés, exécuter des tâches d’inférence localement et recevoir des récompenses en tokens selon leur contribution.
Pour garantir l’intégrité des résultats, Dolphin met en œuvre des mécanismes de vérification et des incitations économiques pour coordonner le comportement des nœuds, notamment l’échantillonnage aléatoire, la revue des tâches et le staking.
Lorsqu’un développeur interagit avec Dolphin Network, les requêtes sont d’abord dirigées vers la couche d’ordonnancement des tâches.
Cette couche analyse le type de tâche, les besoins en GPU et les ressources de modèles. Les modèles d’IA nécessitent des configurations mémoire, des vitesses d’inférence et une puissance de calcul variables ; le réseau adapte donc dynamiquement les requêtes aux nœuds selon leur statut.
Sur une plateforme cloud IA centralisée, ce processus est géré par un centre de données unique. Dans Dolphin, les tâches sont réparties sur un réseau décentralisé de nœuds GPU.
Certaines tâches peuvent être divisées en plusieurs requêtes d’inférence plus petites pour optimiser l’efficacité globale et la concurrence du réseau.
Les nœuds GPU constituent la ressource principale de calcul du Dolphin Network.
Les opérateurs de nœuds déploient généralement un logiciel dédié et autorisent le système à utiliser les GPU locaux pour les tâches d’inférence IA. Lorsqu’une tâche est attribuée, le nœud télécharge le modèle ou les paramètres d’inférence correspondants et réalise le calcul localement.
Une fois la tâche terminée, le nœud soumet les résultats d’inférence au réseau et attend leur vérification pour en valider la conformité. Seules les tâches validées donnent droit à des récompenses en tokens.
Cette approche diffère du mining GPU classique. Alors que les réseaux PoW sont axés sur le calcul de hash, les nœuds GPU de Dolphin réalisent de véritables tâches d’inférence IA, se rapprochant ainsi d’un “marché de puissance de hash disponible”.
L’inférence IA ne se valide pas comme une transaction blockchain, car les résultats ne peuvent généralement pas être confirmés par de simples formules mathématiques. Dolphin s’appuie donc sur des mécanismes complémentaires pour éviter la soumission de résultats incorrects par les nœuds.
L’échantillonnage aléatoire est une méthode courante : des tâches sont sélectionnées au hasard pour revue, afin de vérifier la cohérence des résultats entre plusieurs nœuds. La soumission récurrente de données anormales peut réduire la réputation d’un nœud ou le priver de récompenses.
Certains réseaux IA décentralisés recourent aussi au staking. Les nœuds doivent staker des tokens pour participer, et les comportements malveillants sont sanctionnés sur leurs actifs stakés.
Ces incitations économiques visent à aligner le comportement des nœuds et à renforcer la crédibilité du réseau.
En quoi Dolphin se distingue-t-il de l’inférence cloud IA classique ?
Les plateformes cloud IA traditionnelles reposent sur de grands centres de données centralisés — une entité unique contrôle les clusters GPU, le déploiement des modèles et les services API.
Dolphin adopte une architecture de réseau GPU ouvert. Les nœuds GPU sont apportés par une base d’utilisateurs mondiale, permettant aux développeurs d’accéder à des services d’inférence IA dans un environnement ouvert, tout en réduisant la dépendance à un fournisseur unique.
Dolphin privilégie également les modèles IA ouverts et le partage des ressources. Certains réseaux favorisent le déploiement de modèles open-source, des règles systèmes personnalisées et des scénarios ouverts d’Agent IA.
Cependant, les réseaux IA distribués font face à des défis comme la stabilité, la latence réseau et la qualité variable des nœuds, et restent à un stade précoce de développement.
Quels sont les défis du Dolphin Network ?
Les réseaux d’inférence IA décentralisés offrent ouverture et partage des ressources, mais rencontrent plusieurs défis concrets.
D’abord, les performances des nœuds GPU varient fortement. Les différences de mémoire, de bande passante et de capacité d’inférence affectent la stabilité globale du réseau.
Ensuite, la vérification des résultats d’inférence IA demeure complexe. Contrairement à la blockchain, les résultats IA sont probabilistes, ce qui augmente les coûts de vérification.
À mesure que les modèles d’IA deviennent plus volumineux, l’ordonnancement efficace de clusters GPU à grande échelle dans un environnement distribué devient un enjeu crucial pour les projets DePIN IA.
L’incertitude réglementaire représente aussi un défi. Les modèles IA ouverts peuvent soulever des questions liées aux données, au droit d’auteur et à la génération de contenu ; les réseaux d’infrastructure IA doivent donc gérer des risques réglementaires à long terme.
Résumé
Dolphin Network est un réseau d’inférence IA décentralisé qui associe IA et DePIN, avec pour objectif de bâtir une infrastructure IA ouverte grâce à des nœuds GPU mondiaux. Le réseau coordonne développeurs et nœuds GPU par la planification des tâches, l’inférence distribuée, la vérification aléatoire et le mécanisme d’incitation DPHN.
Comparé aux plateformes cloud IA centralisées traditionnelles, Dolphin mise sur l’ouverture, le partage des ressources et la résistance à la censure, s’affirmant comme une orientation majeure pour l’infrastructure Web3 IA.
FAQ
Comment Dolphin exploite-t-il les nœuds GPU ?
Les détenteurs de GPU peuvent déployer des nœuds, mettre à disposition leurs GPU inutilisés pour exécuter des tâches d’inférence IA et obtenir des récompenses DPHN.
Quelles sont les étapes du processus d’inférence IA chez Dolphin ?
Les principales étapes sont : soumission de la tâche, planification des nœuds, exécution de l’inférence GPU, vérification des résultats et distribution des récompenses.
Pourquoi Dolphin est-il considéré comme un projet DePIN ?
Ses ressources fondamentales sont du matériel GPU réel, et il coordonne une infrastructure distribuée par le biais d’incitations tokenisées.
En quoi Dolphin diffère-t-il des plateformes cloud IA traditionnelles ?
Les plateformes cloud IA traditionnelles reposent sur des centres de données centralisés ; Dolphin s’appuie sur un réseau GPU ouvert pour fournir des services d’inférence IA distribués.
Quel est le rôle de DPHN dans le réseau ?
DPHN sert aux paiements d’inférence IA, à la récompense des nœuds, au staking et constitue une incitation économique au sein du réseau.








