Ingin menghasilkan uang dengan model besar? Wajah baru yang kuat ini memutuskan untuk menurunkan biaya penalaran terlebih dahulu.
Sumber asli: Heart of the Machine
 Sumber gambar: Dihasilkan oleh Unbounded AI
Sumber gambar: Dihasilkan oleh Unbounded AI
Berapa banyak uang yang dibakar oleh bisnis model skala besar? Beberapa waktu lalu, sebuah laporan di Wall Street Journal memberikan jawaban referensi.
Menurut laporan itu, bisnis GitHub Copilot Microsoft (didukung oleh model GPT OpenAI) mengenakan biaya $ 10 per bulan, tetapi biayanya masih rata-rata $ 20 per pengguna. Penyedia layanan AI menghadapi tantangan ekonomi yang signifikan – layanan ini tidak hanya mahal untuk dibangun, tetapi juga sangat mahal untuk dioperasikan.
Seseorang menyamakannya dengan “menggunakan AI untuk meringkas email seperti meminta Lamborghini untuk mengantarkan pizza.”
OpenAI telah menghitung akun yang lebih rinci tentang ini: ketika panjang konteks adalah 8K, biaya setiap token input 1K adalah 3 sen, dan biaya output adalah 6 sen. Saat ini, OpenAI memiliki 180 juta pengguna dan menerima lebih dari 10 juta kueri per hari. Dengan cara ini, untuk mengoperasikan model seperti ChatGPT, OpenAI perlu menginvestasikan sekitar $ 7 juta per hari dalam perangkat keras komputasi yang diperlukan, yang dapat dikatakan sangat mahal.
 Mengurangi biaya inferensi untuk LLM sangat penting, dan meningkatkan kecepatan inferensi adalah jalur kritis yang terbukti. **
Mengurangi biaya inferensi untuk LLM sangat penting, dan meningkatkan kecepatan inferensi adalah jalur kritis yang terbukti. **
Bahkan, komunitas riset telah mengusulkan sejumlah teknologi untuk mempercepat tugas inferensi LLM, termasuk DeepSpeed, FlexGen, vLLM, OpenPPL, FlashDecoding, dan TensorRT-LLM. Secara alami, teknologi ini juga memiliki kelebihan dan kekurangannya sendiri. Di antara mereka, FlashDecoding adalah metode canggih yang diusulkan oleh penulis FlashAttention dan Tri Dao et al. dari tim Universitas Stanford bulan lalu, yang sangat meningkatkan kecepatan inferensi LLM dengan memuat data secara paralel, dan dianggap memiliki potensi besar. Tetapi pada saat yang sama, ini memperkenalkan beberapa overhead komputasi yang tidak perlu, jadi masih ada banyak ruang untuk optimasi.
Untuk mengatasi masalah lebih lanjut, tim gabungan dari Infinigence-AI, Universitas Tsinghua, dan Universitas Jiao Tong Shanghai baru-baru ini mengusulkan metode baru, FlashDecoding ++, yang tidak hanya membawa lebih banyak akselerasi daripada metode sebelumnya (dapat mempercepat inferensi GPU sebesar 2-4x), tetapi yang lebih penting, mendukung GPU NVIDIA dan AMD! Ide intinya adalah untuk mencapai paralelisme sejati dalam perhitungan perhatian melalui pendekatan asinkron, dan untuk mempercepat perhitungan dalam tahap Decode untuk optimasi produk matriks “chunky”. **
 Alamat:
Alamat:
Mempercepat inferensi GPU sebesar 2-4x,
Bagaimana FlashDecoding ++ melakukannya? **
Tugas inferensi LLM umumnya untuk memasukkan sepotong teks (token), dan terus menghasilkan teks atau bentuk konten lainnya melalui perhitungan model LLM.
Perhitungan inferensi LLM dapat dibagi menjadi dua tahap: Prefill dan Decode, di mana tahap Prefill menghasilkan token pertama dengan memahami teks input; Pada fase Decode, token berikutnya adalah output secara berurutan. Dalam dua tahap, perhitungan inferensi LLM dapat dibagi menjadi dua bagian utama: perhitungan perhatian dan perhitungan perkalian matriks.
Untuk komputasi perhatian, pekerjaan yang ada, seperti FlashDecoding, mengimplementasikan pemuatan data paralel dengan operator softmax dalam sharding attention computing. Metode ini memperkenalkan overhead komputasi 20% dalam perhitungan perhatian karena kebutuhan untuk menyinkronkan nilai maksimum di berbagai bagian softmax. Untuk perhitungan perkalian matriks, pada tahap Decode, matriks perkalian kiri sebagian besar muncul sebagai matriks “chunky”, yaitu, jumlah baris umumnya tidak besar (misalnya, <=8), dan mesin inferensi LLM yang ada memperluas jumlah baris menjadi 64 dengan melengkapi 0 untuk mempercepatnya dengan arsitektur seperti Tensor Cores, menghasilkan sejumlah besar perhitungan yang tidak valid (dikalikan dengan 0).
Untuk mengatasi masalah di atas, ide inti dari “FlashDecoding ++” adalah untuk mewujudkan paralelisme sebenarnya dari perhitungan perhatian melalui metode asinkron, dan mempercepat perhitungan dalam tahap Decode untuk optimasi perkalian matriks “Humpty Dumpty”. **
Perhitungan Softmax Sebagian Paralel Asinkron
 *Gambar 1 Perhitungan Softmax Bagian Paralel Asinkron
*Gambar 1 Perhitungan Softmax Bagian Paralel Asinkron
Pekerjaan sebelumnya memasukkan nilai maksimum untuk setiap bagian perhitungan softmax sebagai faktor skala untuk menghindari luapan eksponen e dalam perhitungan softmax, yang menghasilkan overhead sinkronisasi dari berbagai bagian perhitungan softmax (Gambar 1 (a) (b)).
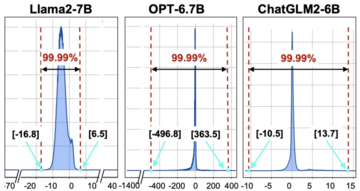 Gambar 2 Distribusi Statistik Nilai Input Softmax
Gambar 2 Distribusi Statistik Nilai Input Softmax
“FlashDecoding ++” menunjukkan bahwa untuk sebagian besar LLM, distribusi input softmax lebih terkonsentrasi. Seperti yang ditunjukkan pada Gambar 2, lebih dari 99,99% input softmax untuk Llama2-7B terkonsentrasi di kisaran [-16,8, 6,5]. Oleh karena itu, “FlashDecoding ++” mengusulkan untuk menggunakan nilai maksimum tetap untuk beberapa perhitungan softmax (Gambar 1 ©), sehingga menghindari sinkronisasi yang sering antara perhitungan softmax yang berbeda. Ketika input dengan probabilitas kecil berada di luar kisaran yang diberikan, perhitungan softmax dari bagian “FlashDecoding ++” ini merosot ke metode perhitungan asli.
Humpty Dumpty Matrix Optimasi Produk
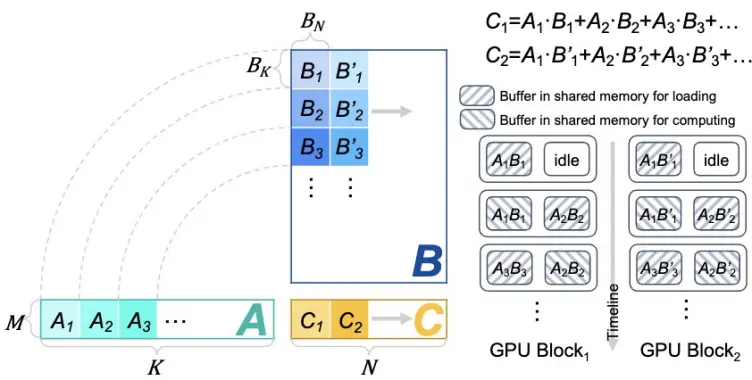 Gbr.3 Perpecahan Perkalian Matriks Humpty Dumpty dan Mekanisme Caching Ganda
Gbr.3 Perpecahan Perkalian Matriks Humpty Dumpty dan Mekanisme Caching Ganda
Karena input ke tahap Decode adalah satu atau beberapa vektor token, produk matriks untuk tahap itu berperilaku dalam bentuk “chunky”. Ambil matriks A×B=C sebagai contoh, di mana bentuk matriks A dan B adalah M×K dan K×N, dan matriks “Humpty Dumpty” mengalikan M ketika M lebih kecil. “FlashDecoding ++” menunjukkan bahwa matriks “Humpty Dumpty” dibatasi oleh cache umum, dan mengusulkan metode pengoptimalan seperti mekanisme cache ganda untuk mempercepatnya (Gbr. 3).
 Gambar 4 Implementasi Perkalian Matriks Adaptif
Gambar 4 Implementasi Perkalian Matriks Adaptif
Selain itu, “FlashDecoding ++” lebih lanjut menunjukkan bahwa pada tahap inferensi LLM, nilai N dan K ditetapkan untuk model tertentu. Oleh karena itu, “FlashDecoding ++” secara adaptif memilih implementasi optimal dari produk matriks sesuai dengan besarnya M.
Mempercepat inferensi GPU sebesar 2-4x
 5 Inferensi LLM platform NVIDIA vs. AMD “FlashDecoding++” (model Llama2-7B, batchsize=1)*
5 Inferensi LLM platform NVIDIA vs. AMD “FlashDecoding++” (model Llama2-7B, batchsize=1)*
Saat ini, FlashDecoding ++ dapat mempercepat inferensi LLM pada backend beberapa GPU, seperti NVIDIA dan AMD (Gambar 5). Dengan mempercepat pembuatan token pertama dalam fase Prefill dan kecepatan pembuatan setiap token dalam fase Decode, “FlashDecoding ++” dapat mempercepat pembuatan teks panjang dan pendek. **FlashDecoding++ mempercepat inferensi rata-rata 37% pada NVIDIA A100 dibandingkan dengan FlashDecoding, dan hingga 2-4x lebih cepat daripada Hugging Face pada backend multi-GPU NVIDIA dan AMD. **
** AI Pemula Kewirausahaan Model Besar: Wuwen Core Dome **
Tiga rekan penulis penelitian ini adalah Dr. Dai Guohao, kepala ilmuwan Wuwen Core Dome dan profesor Shanghai Jiao Tong University, Hong Ke, magang penelitian Wuwen Core Dome dan mahasiswa master Universitas Tsinghua, dan Xu Jiaming, magang penelitian Wuwen Core Dome dan mahasiswa doktoral Universitas Jiao Tong Shanghai. Penulis yang sesuai adalah Profesor Dai Guohao dari Universitas Jiao Tong Shanghai dan Profesor Wang Yu, Dekan Departemen Teknik Elektronik Universitas Tsinghua.
Didirikan pada Mei 2023, tujuannya adalah untuk menciptakan solusi terbaik untuk integrasi perangkat lunak dan perangkat keras untuk model besar, dan FlashDecoding++ telah diintegrasikan ke dalam mesin komputasi model besar “Infini-ACC”. Dengan dukungan “Infini-ACC”, Wuwen Core Dome sedang mengembangkan serangkaian solusi integrasi perangkat lunak dan perangkat keras skala besar, termasuk model skala besar "Infini-Megrez", mesin all-in-one perangkat lunak dan perangkat keras, dll.
Dapat dipahami bahwa “Infini-Megrez” telah berkinerja sangat baik dalam menangani teks panjang, meningkatkan panjang teks yang dapat diproses menjadi token 256k yang memecahkan rekor**, dan pemrosesan sebenarnya sekitar 400.000 kata dari seluruh “Masalah Tiga Tubuh 3: Death Eternal” bukanlah masalah. Ini adalah panjang teks terpanjang yang dapat diproses oleh model besar saat ini.
 Selain itu, model besar “Infini-Megrez” telah mencapai kinerja algoritma tingkat pertama pada dataset seperti C (MEDIUM), MMLU (INGGRIS), CMMLU (medium), dan AGI, dan terus berkembang berdasarkan mesin komputasi “Infini-ACC”.
Selain itu, model besar “Infini-Megrez” telah mencapai kinerja algoritma tingkat pertama pada dataset seperti C (MEDIUM), MMLU (INGGRIS), CMMLU (medium), dan AGI, dan terus berkembang berdasarkan mesin komputasi “Infini-ACC”.