Von Jerry Luo, Kernel Ventures
TL;DR
-
In den Anfängen erforderten öffentliche Chains Knoten im gesamten Netzwerk, um die Datenkonsistenz aufrechtzuerhalten und Sicherheit und Dezentralisierung zu gewährleisten. Mit der Entwicklung des Blockchain-Ökosystems nimmt der Speicherdruck jedoch weiter zu, was zu einem Trend zur Zentralisierung des Knotenbetriebs führt. In dieser Phase muss Layer 1 dringend das Speicherkostenproblem lösen, das durch das Wachstum von TPS verursacht wird.
-
Angesichts dieses Problems müssen Entwickler ein neues Schema zur Speicherung historischer Daten vorschlagen, das Sicherheit, Speicherkosten, Datenlesegeschwindigkeit und die Vielseitigkeit der DA-Schicht berücksichtigt.
-
Bei der Lösung dieses Problems sind viele neue Technologien und Ideen entstanden, darunter Sharding, DAS, Verkle Tree, DA-Zwischenkomponenten usw. Sie versuchten, das Speicherschema der DA-Schicht zu optimieren, indem sie die Datenredundanz reduzierten und die Effizienz der Datenüberprüfung verbesserten.
-
Das derzeitige DA-Schema ist aus Sicht des Datenspeicherorts grob in zwei Kategorien unterteilt, nämlich die Hauptkette DA und die Drittanbieter-DA. Die DA der Hauptkette basiert auf der Perspektive, Daten regelmäßig zu bereinigen und den Datenspeicher zu teilen, um den Speicherdruck auf die Knoten zu reduzieren. Die DA-Designanforderungen von Drittanbietern sind so konzipiert, dass sie der Speicherung dienen und eine vernünftige Lösung für große Datenmengen bieten. Daher ist es hauptsächlich ein Kompromiss zwischen Single-Chain-Kompatibilität und Multi-Chain-Kompatibilität, und es werden drei Lösungen vorgeschlagen: Main-Chain-dedizierter DA, modularer DA und Storage-Public-Chain-DA.
-
Die zahlungsbasierte öffentliche Kette hat extrem hohe Anforderungen an die Sicherheit historischer Daten und ist geeignet, die Hauptkette als DA-Schicht zu verwenden. Für öffentliche Chains, die schon lange laufen und eine große Anzahl von Minern das Netzwerk betreiben, ist es jedoch angemessener, eine DA eines Drittanbieters zu verwenden, die keine Konsensschicht beinhaltet und die Sicherheit berücksichtigt. Die umfassende öffentliche Kette eignet sich besser für die Verwendung von DA-Speicher, der für die Hauptkette mit größerer Datenkapazität, geringeren Kosten und Sicherheit bestimmt ist. Aber angesichts des Bedarfs an Cross-Chain ist auch ein modularer DA eine gute Option.
-
Generell entwickelt sich die Blockchain in die Richtung, Datenredundanz und Multi-Chain-Arbeitsteilung zu reduzieren.
1. Hintergrund
Als Distributed Ledger muss die Blockchain historische Daten auf allen Knoten speichern, um die Sicherheit und Dezentralisierung der Datenspeicherung zu gewährleisten. Da die Richtigkeit jeder Zustandsänderung mit dem vorherigen Zustand (der Quelle der Transaktion) zusammenhängt, sollte eine Blockchain, um die Korrektheit der Transaktion zu gewährleisten, im Prinzip die gesamte Historie von der ersten Transaktion bis zur aktuellen Transaktion speichern. Nehmen wir Ethereum als Beispiel: Selbst wenn die durchschnittliche Größe jedes Blocks auf 20 KB geschätzt wird, hat die Gesamtgröße des aktuellen Ethereum-Blocks 370 GB erreicht, und ein vollständiger Knoten muss neben dem Block selbst auch den Status und die Transaktionsbelege aufzeichnen. Unter Berücksichtigung dieses Teils hat das gesamte Speichervolumen eines einzelnen Knotens 1 TB überschritten, wodurch sich der Betrieb des Knotens auf eine kleine Anzahl von Personen konzentriert.
Die neueste Blockhöhe von Ethereum, Bildquelle: Etherscan
2. DA-Leistungskennzahlen
2.1 Sicherheit
Im Vergleich zur Datenbank- oder Linked-List-Speicherstruktur ergibt sich die Unveränderlichkeit der Blockchain aus der Tatsache, dass die neu generierten Daten durch historische Daten verifiziert werden können, so dass die Gewährleistung der Sicherheit ihrer historischen Daten die erste Überlegung bei der DA-Schichtspeicherung ist. Für die Bewertung der Datensicherheit des Blockchain-Systems analysieren wir häufig den Umfang der Datenredundanz und die Verifizierungsmethode der Datenverfügbarkeit
Anzahl der Redundanz: Für die Redundanz von Daten im Blockchain-System kann es hauptsächlich die folgenden Rollen spielen: Erstens, wenn die Anzahl der Redundanzen im Netzwerk größer ist, wenn der Validator den Kontostatus in einem historischen Block überprüfen muss, um die aktuelle Transaktion zu verifizieren, kann er die größte Anzahl von Stichproben als Referenz abrufen und die Daten auswählen, die von der Mehrheit der Knoten aufgezeichnet wurden. Da Daten in herkömmlichen Datenbanken nur in Form von Schlüssel-Wert-Paaren auf einem bestimmten Knoten gespeichert werden, sind die Angriffskosten extrem gering, um historische Daten nur auf einem einzigen Knoten zu ändern, und theoretisch gilt: Je redundanter die Daten, desto glaubwürdiger die Daten. Gleichzeitig gilt: Je mehr Knoten gespeichert sind, desto geringer ist die Wahrscheinlichkeit, dass die Daten verloren gehen. Dies kann auch mit zentralisierten Servern verglichen werden, auf denen Web2-Spiele gespeichert sind, und sobald alle Backend-Server heruntergefahren sind, wird es eine vollständige Abschaltung geben. Mehr ist jedoch nicht besser, denn jede Redundanz bringt zusätzlichen Speicherplatz, und zu viel Datenredundanz führt zu einem übermäßigen Speicherdruck auf das System, und eine gute DA-Schicht sollte eine geeignete Redundanzmethode wählen, um ein Gleichgewicht zwischen Sicherheit und Speichereffizienz herzustellen.
Datenverfügbarkeitsprüfung: Die Redundanz stellt sicher, dass genügend Datensätze im Netzwerk vorhanden sind, aber die zu verwendenden Daten müssen auch auf Richtigkeit und Vollständigkeit überprüft werden. In dieser Phase ist die am häufigsten verwendete Verifizierungsmethode in der Blockchain der kryptografische Verpflichtungsalgorithmus, der eine kleine kryptografische Verpflichtung für das gesamte Netzwerk zur Aufzeichnung beibehält, und diese Verpflichtung wird durch Mischen von Transaktionsdaten erreicht. Um die Authentizität historischer Daten zu testen, ist es notwendig, die kryptografische Zusage durch die Daten wiederherzustellen, zu überprüfen, ob die durch die Wiederherstellung erhaltene kryptografische Zusage mit den Aufzeichnungen des gesamten Netzwerks übereinstimmt, und wenn sie konsistent ist, wird die Verifizierung bestanden. Häufig verwendete Algorithmen zur Passwortüberprüfung sind Merkle Root und Verkle Root. Der Algorithmus zur Überprüfung der Datenverfügbarkeit mit hoher Sicherheit benötigt nur sehr wenige Verifizierungsdaten und kann historische Daten schnell verifizieren.
2.2 Lagerkosten
Unter der Prämisse, die grundlegende Sicherheit zu gewährleisten, besteht das nächste Kernziel, das in der DA-Schicht erreicht werden soll, darin, die Kosten zu senken und die Effizienz zu steigern. Die erste besteht darin, die Speicherkosten zu senken, d. h. den Speicherbedarf zu reduzieren, der durch das Speichern von Daten pro Größeneinheit verursacht wird, ohne den Unterschied in der Hardwareleistung zu berücksichtigen. In dieser Phase besteht die wichtigste Möglichkeit, die Speicherkosten in der Blockchain zu senken, darin, die Sharding-Technologie einzuführen und Rewarded Storage zu verwenden, um sicherzustellen, dass Daten effektiv gespeichert werden, und die Anzahl der Datensicherungen zu reduzieren. Es ist jedoch nicht schwer, aus den oben genannten Verbesserungsmethoden zu erkennen, dass es eine Spielbeziehung zwischen Speicherkosten und Datensicherheit gibt, und die Verringerung der Speicherbelegung bedeutet oft eine Verringerung der Sicherheit. Daher muss eine gute DA-Schicht die Speicherkosten mit der Datensicherheit in Einklang bringen. Wenn es sich bei der DA-Schicht um eine separate öffentliche Kette handelt, ist es außerdem erforderlich, die Kosten zu senken, indem der Zwischenprozess des Datenaustauschs minimiert wird, und die Indexdaten müssen für nachfolgende Abfrageaufrufe in jedem Transitprozess aufbewahrt werden, d. h., je länger der Aufrufprozess dauert, desto mehr Indexdaten bleiben übrig und die Speicherkosten werden erhöht. Schließlich stehen die Kosten für die Datenspeicherung in direktem Zusammenhang mit der Dauerhaftigkeit der Daten. Im Allgemeinen gilt: Je höher die Speicherkosten von Daten, desto schwieriger ist es für die öffentliche Kette, Daten dauerhaft zu speichern.
2.3 Lesegeschwindigkeit der Daten
Sobald die Kostensenkung erreicht ist, besteht der nächste Schritt in Effizienzsteigerungen, d. h. in der Fähigkeit, Daten schnell aus der DA-Schicht abzurufen, wenn sie verwendet werden müssen. Dieser Prozess umfasst zwei Schritte, der erste besteht darin, nach den Knoten zu suchen, die Daten speichern, dieser Prozess ist hauptsächlich für die öffentliche Kette, die nicht die Datenkonsistenz des gesamten Netzwerks erreicht hat, wenn die öffentliche Kette die Datensynchronisierung der Knoten des gesamten Netzwerks erreicht hat, kann der Zeitverbrauch dieses Prozesses ignoriert werden. Zweitens ist in den Mainstream-Blockchain-Systemen in dieser Phase, einschließlich Bitcoin, Ethereum und Filecoin, die Knotenspeichermethode die Leveldb-Datenbank. In Leveldb werden Daten auf drei Arten gespeichert. Die erste besteht darin, dass die Daten, die on-the-fly geschrieben werden, in einer Datei vom Typ memtable gespeichert werden, und wenn die memtable voll ist, wird der Dateityp von memtable in unveränderliche memtable geändert. Beide Dateitypen werden im Arbeitsspeicher abgelegt, aber die unveränderliche Memtable-Datei kann nicht mehr geändert werden und kann nur Daten daraus lesen. Der im IPFS-Netzwerk verwendete Hot-Speicher speichert die Daten in diesem Teil, und sie können schnell aus dem Speicher gelesen werden, wenn sie aufgerufen werden, aber der mobile Speicher eines gewöhnlichen Knotens befindet sich oft auf der Gigabyte-Ebene, was leicht langsam zu schreiben ist, und wenn der Knoten ausfällt und andere abnormale Bedingungen auftreten, gehen die Daten im Speicher dauerhaft verloren. Wenn Sie möchten, dass Ihre Daten persistent gespeichert werden, müssen Sie sie als SST-Datei auf einem Solid-State-Laufwerk (SSD) speichern, aber Sie müssen die Daten zuerst in den Arbeitsspeicher lesen, was die Geschwindigkeit der Datenindizierung erheblich verlangsamt. Bei Systemen mit Shardspeicher erfordert die Datenwiederherstellung das Senden von Datenanforderungen an mehrere Knoten und deren Wiederherstellung, wodurch auch die Lesegeschwindigkeit der Daten verlangsamt wird.
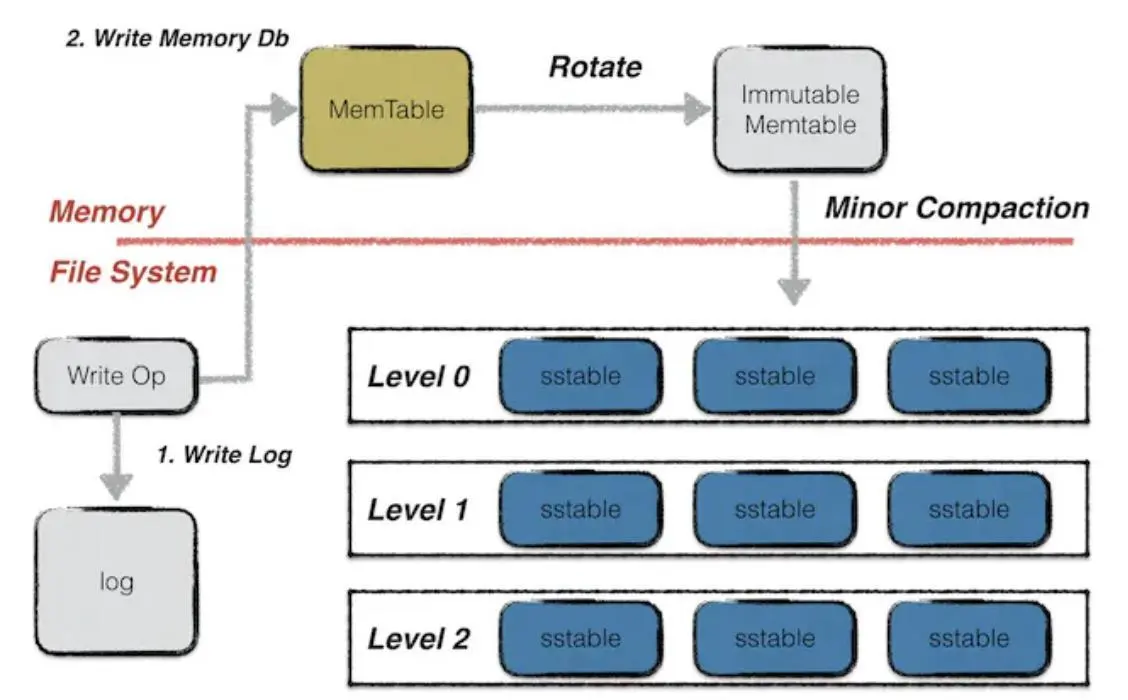
Leveldb-Datenspeichermethode, Bildquelle: Leveldb-Handbook
2.4 DA-Layer-Gemeinsamkeit
Mit der Entwicklung von DeFi und den Problemen von CEXs wächst auch die Nachfrage nach Cross-Chain-Transaktionen von dezentralen Vermögenswerten. Unabhängig davon, ob es sich um einen Cross-Chain-Mechanismus von Hash-Locking, Notar oder Relay Chain handelt, ist es unvermeidlich, die historischen Daten auf den beiden Chains gleichzeitig zu ermitteln. Der Kern dieses Problems liegt in der Trennung der Daten auf den beiden Chains, und eine direkte Kommunikation kann in verschiedenen dezentralen Systemen nicht erreicht werden. Daher wird in dieser Phase eine Lösung vorgeschlagen, indem der Speichermodus der DA-Schicht geändert wird, die die historischen Daten mehrerer öffentlicher Ketten auf derselben vertrauenswürdigen öffentlichen Kette speichert und bei der Überprüfung nur die Daten auf dieser öffentlichen Kette aufrufen muss. Dies erfordert, dass die DA-Schicht in der Lage ist, eine sichere Kommunikationsmethode mit verschiedenen Arten von öffentlichen Ketten einzurichten, d. h. die DA-Schicht hat eine gute Vielseitigkeit.
3. DA-bezogene Technologieerkundung
3.1 Sharding
- In einem traditionellen verteilten System wird eine Datei nicht in vollständiger Form auf einem Knoten gespeichert, sondern die ursprünglichen Daten werden in mehrere Blöcke aufgeteilt und in jedem Knoten wird ein Block gespeichert. Und Blöcke neigen dazu, nicht nur auf einem Knoten gespeichert zu werden, sondern entsprechende Backups auf anderen Knoten zu haben, was in bestehenden verteilten Mainstream-Systemen normalerweise auf 2 gesetzt ist. Dieser Sharding-Mechanismus kann den Speicherdruck auf einen einzelnen Knoten reduzieren, die Gesamtkapazität des Systems auf die Summe der Speicherkapazität jedes Knotens erweitern und die Sicherheit des Speichers durch geeignete Datenredundanz gewährleisten. Der Sharding-Ansatz, der in einer Blockchain verfolgt wird, ist im Großen und Ganzen ähnlich, aber es gibt Unterschiede in den Besonderheiten. Da jeder Knoten in der Blockchain standardmäßig nicht vertrauenswürdig ist, wird zunächst eine ausreichend große Datenmenge benötigt, um die spätere Datenauthentizität im Prozess der Implementierung von Sharding zu sichern, so dass die Anzahl der Sicherungen dieses Knotens viel mehr als 2 betragen muss. Wenn in einem Blockchain-System mit diesem Speicherschema die Gesamtzahl der Validatoren T und die Anzahl der Shards N ist, sollte die Anzahl der Backups im Idealfall T/N sein. Die zweite ist die Speicherprozedur von Block, das traditionelle verteilte System hat weniger Knoten, so dass es oft ein Knoten ist, der sich an mehrere Datenblöcke anpasst, die erste besteht darin, die Daten durch den konsistenten Hashing-Algorithmus auf den Hash-Ring abzubilden, und dann speichert jeder Knoten eine Anzahl von Datenblöcken in einem bestimmten Bereich, und es kann akzeptiert werden, dass ein Knoten keine Speicheraufgabe in einem bestimmten Speicher zuweist. Auf der Blockchain ist die Zuweisung jedes Knotens zu einem Block kein zufälliges Ereignis mehr, sondern ein unvermeidliches Ereignis, und jeder Knoten wählt nach dem Zufallsprinzip einen Block für die Speicherung aus, was durch die Berechnung der Anzahl der Shards mit dem Ergebnis des Datenhashs mit den Originaldaten des Blocks und den eigenen Informationen des Knotens vervollständigt wird. Unter der Annahme, dass jedes Datenelement in N Blöcke unterteilt ist, beträgt die tatsächliche Speichergröße jedes Knotens nur 1/N der ursprünglichen Größe. Durch die entsprechende Einstellung von N kann ein Gleichgewicht zwischen dem wachsenden TPS und dem Speicherdruck des Knotens erreicht werden.
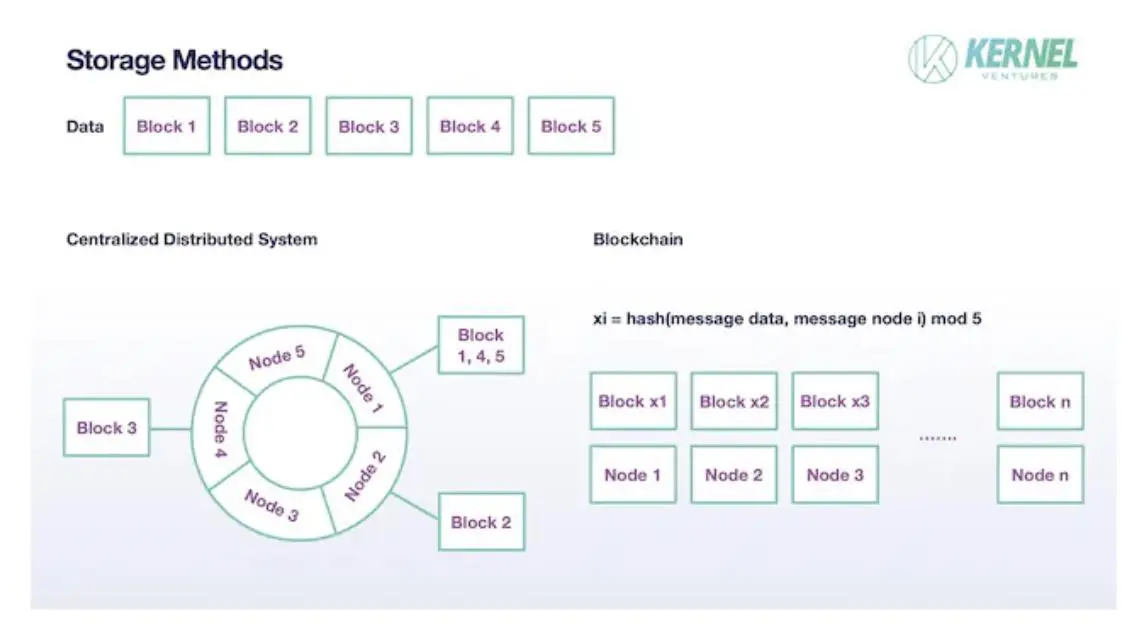
Wie Daten nach Sharding gespeichert werden, Bildquelle: Kernel Ventures
3.2 DAS (Data Availability Sampling)
Die DAS-Technologie basiert auf der weiteren Optimierung von Sharding in Bezug auf Speichermethoden. Beim Sharding kann aufgrund der einfachen zufälligen Speicherung von Knoten ein bestimmter Block verloren gehen. Zweitens ist es für die Shard-Daten auch sehr wichtig, wie die Authentizität und Integrität der Daten während des Wiederherstellungsprozesses bestätigt werden kann. In DAS werden diese beiden Probleme durch Eraser-Code und KZG-Polynombindungen gelöst.
Eraser-Code: In Anbetracht der großen Anzahl von Validatoren auf Ethereum ist die Wahrscheinlichkeit, dass ein Block von keinem Node gespeichert wird, fast null, aber theoretisch besteht immer noch die Möglichkeit, dass eine solche Extremsituation eintritt. Um diese mögliche Gefahr eines Speicherverlusts zu mindern, werden die ursprünglichen Daten nicht direkt in Blöcke für die Speicherung unterteilt, sondern die ursprünglichen Daten den Koeffizienten eines Polynoms n-ter Ordnung zugeordnet, und dann werden 2n Punkte auf dem Polynom genommen, und der Knoten wählt nach dem Zufallsprinzip einen von ihnen für die Speicherung aus. Für dieses Polynom n-ter Ordnung werden nur n+1 Punkte für die Wiederherstellung benötigt, so dass nur die Hälfte der Blöcke von den Knoten ausgewählt werden muss, um die ursprünglichen Daten wiederherzustellen. Durch den Eraser-Code wird die Sicherheit der Datenspeicherung und die Fähigkeit des Netzwerks, Daten wiederherzustellen, verbessert.
KZG Polynomial Promise: Ein sehr wichtiger Teil der Datenspeicherung ist die Überprüfung der Datenauthentizität. In Netzwerken, die keinen Eraser-Code verwenden, gibt es verschiedene Möglichkeiten, den Prozess zu validieren, aber wenn der obige Eraser-Code eingeführt wird, um die Datensicherheit zu verbessern, ist es angemessener, KZG-Polynom-Verpflichtungen zu verwenden. Das KZG-Polynom verspricht, den Inhalt eines einzelnen Blocks in Form von Polynomen direkt zu verifizieren, wodurch die Notwendigkeit entfällt, Polynome in Binärdaten wiederherzustellen, und die Verifizierungsform ähnelt im Allgemeinen der von Merkle Tree, aber es sind keine spezifischen Pfadknotendaten erforderlich, nur KZG-Stamm- und Blockdaten werden benötigt, um seine Authentizität zu überprüfen.
3.3 DA-Layer-Datenüberprüfungsmodus
Die Datenvalidierung stellt sicher, dass die vom Knoten abgerufenen Daten nicht manipuliert wurden und nicht verloren gegangen sind. Um die Datenmenge und den Rechenaufwand im Verifikationsprozess so weit wie möglich zu reduzieren, übernimmt die DA-Schicht derzeit die Baumstruktur als Mainstream-Verifikationsmethode. Die einfachste Form besteht darin, den Merkle-Baum für die Verifizierung zu verwenden, der in Form eines vollständigen Binärbaums aufgezeichnet wird und nur eine Merkle-Wurzel und den Hash-Wert des Teilbaums auf der anderen Seite des zu verifizierenden Knotenpfads beibehalten muss, und die Zeitkomplexität der Verifizierung ist O(logN)-Ebene (logN ist standardmäßig log2(N), wenn die Zahl nicht basiert). Obwohl der Validierungsprozess stark vereinfacht wurde, hat sich die Datenmenge im Validierungsprozess im Allgemeinen mit der Zunahme der Daten erhöht. Um das Problem der Erhöhung des Verifizierungsumfangs zu lösen, wird in dieser Phase eine andere Verifizierungsmethode, Verkle Tree, vorgeschlagen. Zusätzlich zum Speichern von Werten wird jeder Knoten im Verkle-Baum auch mit einem Vector Commitment geliefert, durch den Wert des ursprünglichen Knotens und diesen Commitment-Beweis können Sie die Authentizität der Daten schnell überprüfen, ohne den Wert anderer Schwesterknoten aufzurufen, wodurch sich die Anzahl der Berechnungen für jede Verifizierung nur auf die Tiefe des Verkle-Baums bezieht, die eine feste Konstante ist, wodurch die Verifizierungsgeschwindigkeit erheblich beschleunigt wird. Die Berechnung von Vector Commitment erfordert jedoch die Beteiligung aller Schwesterknoten in derselben Schicht, was die Kosten für das Schreiben und Ändern von Daten erheblich erhöht. Für historische Daten, die dauerhaft gespeichert werden und nicht manipuliert werden können, eignet sich Verkle Tree jedoch hervorragend. Darüber hinaus gibt es auch Varianten des Merkle-Baums und des Verkle-Baums in Form von K-ary, und ihr spezifischer Implementierungsmechanismus ist ähnlich, aber die Anzahl der Teilbäume unter jedem Knoten wird geändert, und der Vergleich ihrer spezifischen Leistung ist in der folgenden Tabelle zu sehen.
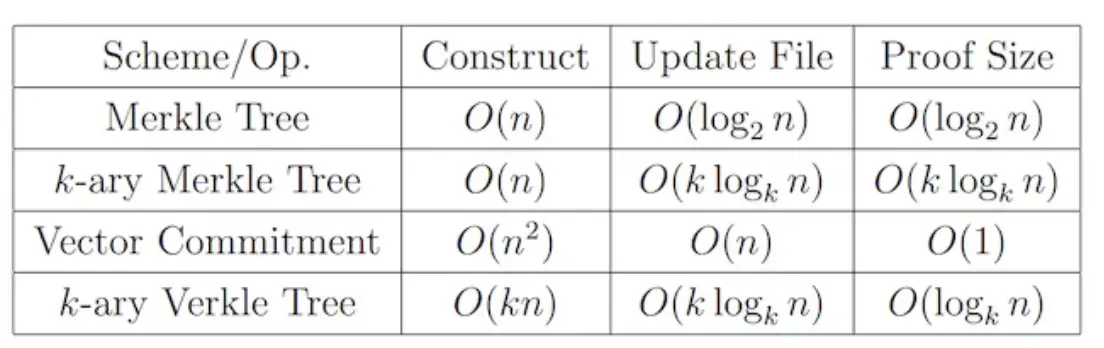
Vergleich von Datenverifizierungsmethoden und Zeitleistung, Bildquelle: Verkle Trees
3.4 Generische DA-Middleware
Die kontinuierliche Erweiterung der Blockchain-Ökologie hat zu einem Anstieg der Anzahl öffentlicher Chains geführt. Aufgrund der Vorteile und der Unersetzlichkeit jeder öffentlichen Kette in ihren jeweiligen Bereichen ist es fast unmöglich, dass die öffentliche Layer1-Kette in kurzer Zeit vereinheitlicht wird. Mit der Entwicklung von DeFi und den Problemen der CEXs wächst jedoch auch die Nachfrage nach dezentralen Cross-Chain-Handelsaktiven. Infolgedessen hat die DA-Layer-Multi-Chain-Datenspeicherung, die Sicherheitsprobleme beim Cross-Chain-Datenaustausch beseitigen kann, immer mehr Aufmerksamkeit erhalten. Um jedoch historische Daten aus verschiedenen öffentlichen Ketten zu akzeptieren, ist es notwendig, dass die DA-Schicht ein dezentrales Protokoll für die standardisierte Speicherung und Verifizierung von Datenflüssen bereitstellt, wie z. B. kvye, eine auf Arweave basierende Speicher-Middleware, die die Initiative ergreift, Daten aus der Kette zu erfassen, und alle Daten auf der Kette in einer Standardform an Arweave speichern kann, um die Unterschiede im Datenübertragungsprozess zu minimieren. Relativ gesehen interagiert Layer2, das sich auf die Bereitstellung von DA-Layer-Datenspeichern für eine bestimmte öffentliche Kette spezialisiert hat, mit Daten über interne Sharing-Nodes, was die Interaktionskosten senkt und die Sicherheit verbessert, hat jedoch relativ große Einschränkungen und kann nur Dienste für bestimmte öffentliche Chains bereitstellen.
4. DA-Tier-Speicherschema
4.1 Mainchain-DA
4.1.1 Klasse DankSharding
Es gibt keinen eindeutigen Namen für diese Art von Speicherschema, und der prominenteste Vertreter dieser Art von Speicherschema ist DankSharding auf Ethereum, daher wird in diesem Artikel das DankSharding-ähnliche Schema verwendet. Diese Art von Lösung verwendet hauptsächlich die beiden oben genannten DA-Speichertechnologien, Sharding und DAS. Zuerst teilt Sharding die Daten in geeignete Teile auf und ermöglicht es dann jedem Knoten, einen Datenblock in Form eines DAS für die Speicherung zu extrahieren. Wenn es genügend Knoten im gesamten Netzwerk gibt, können wir eine größere Anzahl von Shards N nehmen, so dass der Speicherdruck jedes Knotens nur 1/N des Originals beträgt, um das N-fache der gesamten Speicherplatzerweiterung zu erreichen. Um sicherzustellen, dass im Extremfall kein Block in einem Block gespeichert wird, verschlüsselt DankSharding die Daten mit Eraser Code, und nur die Hälfte der Daten kann vollständig wiederhergestellt werden. Schließlich verwendet der Datenvalidierungsprozess die Struktur des Verkle-Baums und die polynomiale Verpflichtung, um eine schnelle Validierung zu erreichen.
4.1.2 Kurzzeitlagerung
Eine der einfachsten Möglichkeiten, Daten für DA in der Hauptkette zu verarbeiten, besteht darin, historische Daten für einen kurzen Zeitraum zu speichern. Im Wesentlichen spielt die Blockchain die Rolle eines öffentlichen Ledgers, das Änderungen am Inhalt des Ledgers unter der Prämisse des gesamten Netzwerks als Zeuge realisiert, ohne dass eine dauerhafte Speicherung erforderlich ist. Nehmen wir Solana als Beispiel: Obwohl die historischen Daten mit Arweave synchronisiert werden, speichern die Mainnet-Knoten nur die Transaktionsdaten der letzten zwei Tage. In der öffentlichen Kette, die auf Kontoaufzeichnungen basiert, behalten die historischen Daten jedes Moments den endgültigen Zustand des Kontos in der Blockchain bei, was ausreicht, um eine Verifizierungsgrundlage für den nächsten Moment der Änderung zu bieten. Für Projekte mit besonderen Datenbedürfnissen vor diesem Zeitraum können sie diese auf anderen dezentralen öffentlichen Chains oder von vertrauenswürdigen Dritten speichern. Das bedeutet, dass Personen, die zusätzliche Daten benötigen, für die Speicherung historischer Daten bezahlen müssen.
4.2 DAs von Drittanbietern
4.2.1 Mainchain dedizierter DA: EthStorage
DA für die Hauptkette:D Das Wichtigste in Schicht A ist die Sicherheit der Datenübertragung, und die sicherste in dieser Hinsicht ist die DA der Hauptkette. Der Main-Chain-Speicher ist jedoch durch Speicherplatz und den Wettbewerb um Ressourcen begrenzt, so dass DA von Drittanbietern die bessere Wahl ist, wenn die Menge der Netzwerkdaten schnell wächst, wenn Sie eine langfristige Speicherung von Daten erreichen möchten. Wenn der Drittanbieter-DA eine höhere Kompatibilität mit dem Mainnet aufweist, kann er die gemeinsame Nutzung von Knoten realisieren und eine höhere Sicherheit beim Datenaustausch bieten. Unter der Prämisse, die Sicherheit zu berücksichtigen, wird es daher enorme Vorteile für die DA geben, die der Hauptkette gewidmet ist. Am Beispiel von Ethereum ist eine der Grundanforderungen an die DA der Hauptkette, dass sie mit EVM kompatibel sein kann, um die Interoperabilität mit Ethereum-Daten und -Verträgen zu gewährleisten, und zu den repräsentativen Projekten gehören Topia, EthStorage usw. Unter ihnen ist EthStorage derzeit in Bezug auf die Kompatibilität am weitesten entwickelt, da es neben der Kompatibilität auf EVM-Ebene auch relevante Schnittstellen zur Verbindung mit Ethereum-Entwicklungstools wie Remix und Hardhat einrichtet, um Kompatibilität auf der Ebene des Ethereum-Entwicklungstools zu erreichen.
EthStorage: EthStorage ist eine von Ethereum unabhängige öffentliche Chain, aber die Nodes, die darauf laufen, sind den Ethereum-Nodes überlegen, d.h. die Nodes, auf denen EthStorage läuft, können gleichzeitig auch Ethereum ausführen, und EthStorage kann direkt über den Opcode auf Ethereum betrieben werden. Im Speichermodell von EthStorage, das nur eine kleine Menge an Metadaten für die Indizierung auf dem Ethereum-Mainnet speichert, entsteht im Wesentlichen eine dezentrale Datenbank für Ethereum. In der aktuellen Lösung hat EthStorage die Interaktion zwischen dem Ethereum-Mainnet und EthStorage implementiert, indem es einen EthStorage-Vertrag im Ethereum-Mainnet bereitgestellt hat. Wenn Ethereum Daten hinterlegen möchte, muss es die put()-Funktion im Vertrag aufrufen, und die Eingabeparameter sind zwei Byte-Variablen key, data, wobei data die zu hinterlegenden Daten darstellt, und key ist seine Identifizierung im Ethereum-Netzwerk, was als ähnlich wie die Existenz von CID in IPFS angesehen werden kann. Nachdem das (Schlüssel-, Daten-) Paar erfolgreich im EthStorage-Netzwerk gespeichert wurde, generiert EthStorage ein kvldx und gibt es an das Ethereum-Mainnet zurück, das dem Schlüssel auf Ethereum entspricht, und dieser Wert entspricht der Speicheradresse der Daten auf EthStorage, so dass das Problem der Speicherung einer großen Datenmenge nun geändert wird, um ein einzelnes (Schlüssel, kvldx) Paar zu speichern, was die Speicherkosten des Ethereum-Mainnets erheblich reduziert. Wenn Sie die zuvor gespeicherten Daten aufrufen müssen, müssen Sie die Funktion get() in EthStorage verwenden und den Schlüsselparameter eingeben, und Sie können eine schnelle Suche nach den Daten auf EthStorage über kvldx durchführen, die auf Ethereum gespeichert sind.
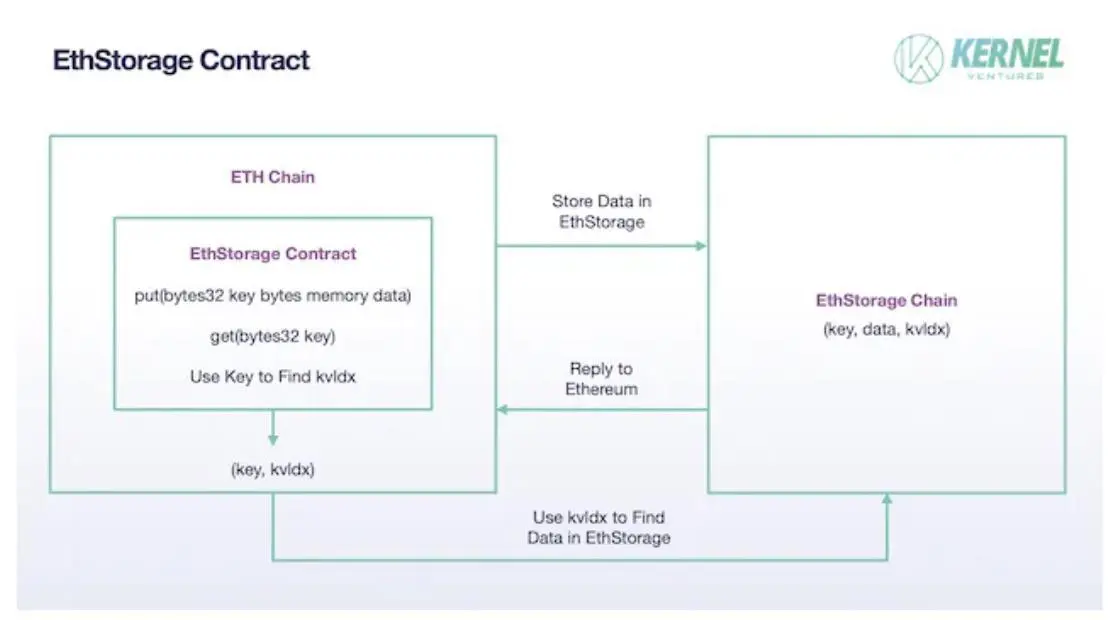
EthStorage-Vertrag, Bildquelle: Kernel Ventures
In Bezug auf die Art und Weise, wie Knoten Daten speichern, lehnt sich EthStorage an das Muster von Arweave an. Zunächst einmal wird eine große Anzahl von (k,v)-Paaren aus ETH aufgeteilt, und jedes Sharding enthält eine feste Anzahl von (k,v)-Datenpaaren, von denen es auch eine Begrenzung für die spezifische Größe jedes (k,v)-Paares gibt, um die Fairness der Workload-Größe bei der Speicherung von Belohnungen für Miner zu gewährleisten. Für die Ausgabe von Belohnungen müssen Sie überprüfen, ob der Knoten Daten speichert. Dabei teilt EthStorage ein Sharding (Terabyte-Größe) in eine große Anzahl von Chunks auf und hält zur Validierung eine Merkle-Wurzel im Ethereum-Mainnet. Als nächstes muss der Miner eine Nonce bereitstellen, um die Adressen mehrerer Chunks durch einen zufälligen Algorithmus mit dem Hash des vorherigen Blocks auf EthStorage zu generieren, und der Miner muss die Daten dieser Chunks bereitstellen, um zu beweisen, dass er tatsächlich das gesamte Sharding gespeichert hat. Diese Nonce kann jedoch nicht beliebig ausgewählt werden, da der Knoten sonst eine geeignete Nonce auswählt, die nur seinem gespeicherten Chunk entspricht, um die Verifizierung zu bestehen, so dass diese Nonce den generierten Chunk nach dem Mischen und Hashen dazu bringen muss, die Netzwerkanforderungen zu erfüllen, und nur der erste Knoten, der den Nonce- und Random-Access-Beweis übermittelt, kann die Belohnung erhalten.
4.2.2 Modularer DA: Celestia
Blockchain-Modul: In dieser Phase sind die Transaktionen, die von der öffentlichen Layer1-Chain ausgeführt werden müssen, hauptsächlich in die folgenden vier Teile unterteilt: (1) Entwerfen der zugrunde liegenden Logik des Netzwerks, Auswählen von Validatoren auf eine bestimmte Weise, Schreiben von Blöcken und Verteilen von Belohnungen an Netzwerkbetreuer, (2) Verpacken und Verarbeiten von Transaktionen und Veröffentlichen verwandter Transaktionen, (3) Verifizieren der Transaktionen, die in die Kette aufgenommen werden sollen, und Bestimmen des Endzustands und (4) Speichern und Pflegen historischer Daten auf der Blockchain. Abhängig von den ausgeführten Funktionen können wir die Blockchain in vier Module unterteilen, nämlich die Konsensschicht, die Ausführungsschicht, die Abwicklungsschicht und die Datenverfügbarkeitsschicht (DA-Schicht).
Modulares Blockchain-Design: Lange Zeit waren diese vier Module in eine öffentliche Chain integriert, und eine solche Blockchain wird als monolithische Blockchain bezeichnet. Diese Form ist stabiler und einfacher zu warten, übt aber auch viel Druck auf eine einzelne öffentliche Kette aus. In der Praxis schränken sich diese vier Module gegenseitig ein und konkurrieren um die begrenzten Rechen- und Speicherressourcen der öffentlichen Kette. Wenn Sie beispielsweise die Verarbeitungsgeschwindigkeit der Verarbeitungsschicht erhöhen, erhöht sich der Speicherdruck auf die Datenverfügbarkeitsschicht, und die Gewährleistung der Sicherheit der Ausführungsschicht erfordert komplexere Authentifizierungsmechanismen, die die Transaktionsverarbeitung verlangsamen. Daher ist die Entwicklung öffentlicher Ketten oft mit Kompromissen zwischen diesen vier Modulen konfrontiert. Um den Engpass bei der Verbesserung der Leistung dieser öffentlichen Kette zu durchbrechen, schlugen die Entwickler ein modulares Blockchain-Schema vor. Die Kernidee der modularen Blockchain besteht darin, eines oder mehrere der oben genannten vier Module zu trennen und an eine separate Public-Chain-Implementierung zu übergeben. Auf diese Weise können Sie sich auf der öffentlichen Chain nur auf die Verbesserung der Transaktionsgeschwindigkeit oder der Speicherkapazität konzentrieren und die bisherigen Einschränkungen durchbrechen, die durch den Short-Board-Effekt auf die Gesamtleistung der Blockchain verursacht wurden.
Modularer DA: Der komplexe Ansatz, die DA-Schicht vom Blockchain-Geschäft zu trennen und an eine einzige öffentliche Chain zu übergeben, gilt als praktikable Lösung für die wachsenden historischen Daten von Layer 1. Die Exploration in diesem Gebiet befindet sich noch in einem frühen Stadium, wobei Celestia derzeit das repräsentativste Projekt ist. In Bezug auf die spezifische Speichermethode lehnt sich Celestia an die Speichermethode von Danksharding an, die darin besteht, die Daten in mehrere Blöcke aufzuteilen, einen Teil davon von jedem Knoten für die Speicherung zu extrahieren und die Datenintegrität mit der KZG-Polynomverpflichtung zu überprüfen. Gleichzeitig verwendet Celestia fortschrittliche 2D-RS-Erasure-Coding-Coding, um die Originaldaten in Form einer kk-Matrix neu zu schreiben, und schließlich können nur 25 % der ursprünglichen Daten wiederhergestellt werden. Der Daten-Sharding-Speicher multipliziert jedoch im Wesentlichen nur die Speicherauslastung der Knoten im gesamten Netzwerk um einen Faktor auf das gesamte Datenvolumen, und der Speicherdruck und das Datenvolumen der Knoten bleiben weiterhin linear wachsen. Da Layer 1 die Transaktionsgeschwindigkeit weiter verbessert, kann die Speicherauslastung der Knoten eines Tages immer noch einen inakzeptablen Schwellenwert erreichen. Um dieses Problem zu lösen, wurde die IPLD-Komponente in Celestia zur Verarbeitung eingeführt. Die Daten in der kk-Matrix werden nicht direkt auf Celestia gespeichert, sondern im LL-IPFS-Netzwerk, und nur der CID-Code dieser Daten auf IPFS wird im Knoten gespeichert. Wenn ein Benutzer Verlaufsdaten anfordert, sendet der Knoten die entsprechende CID an die IPLD-Komponente und verwendet die CID, um die Rohdaten auf IPFS aufzurufen. Wenn Daten auf IPFS vorhanden sind, werden sie über IPLD-Komponenten und -Knoten zurückgegeben, und wenn dies nicht der Fall ist, können sie nicht zurückgegeben werden.
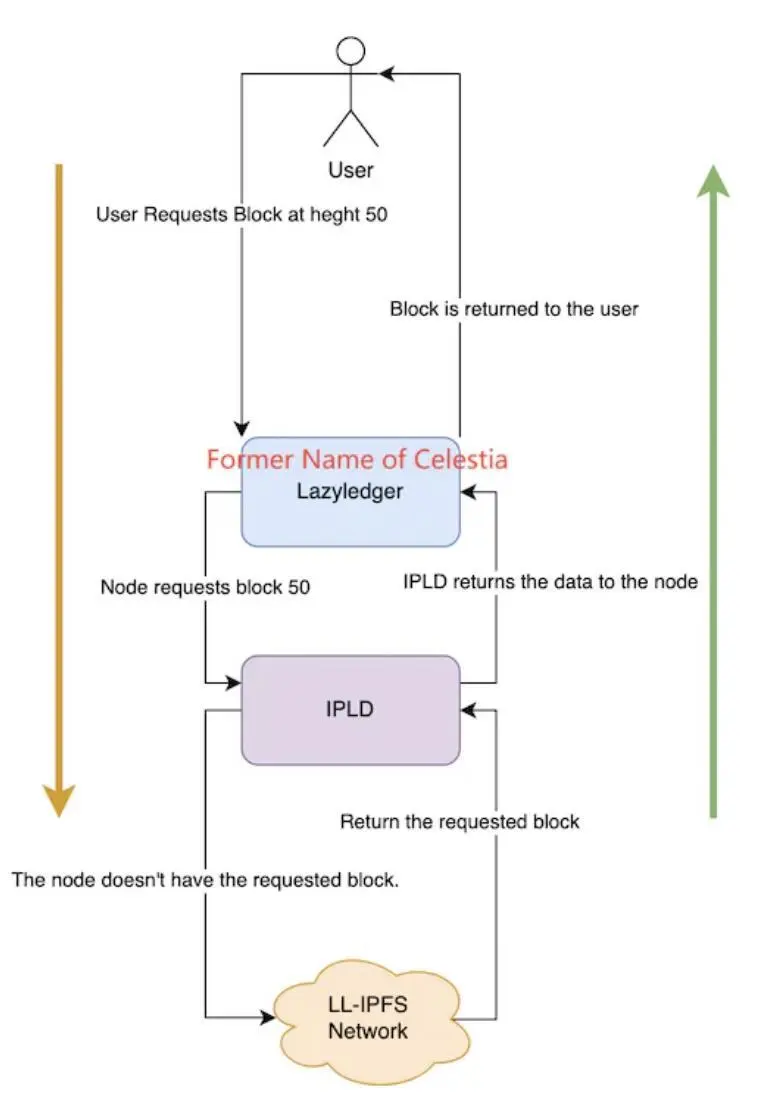
Wie Celestia-Daten gelesen werden, Bildquelle: Celestia Core
Celestia: Am Beispiel von Celestia können wir einen Blick auf die Anwendung der modularen Blockchain bei der Lösung des Speicherproblems von Ethereum werfen. Der Rollup-Knoten sendet die verpackten und verifizierten Transaktionsdaten an Celestia und speichert die Daten auf Celestia, in diesem Prozess speichert Celestia nur die Daten ohne allzu großes Bewusstsein, und schließlich zahlt der Rollup-Knoten entsprechend der Größe des Speicherplatzes die entsprechenden tia-Token als Speichergebühren an Celestia. Der Speicher in Celstia nutzt DAS und Erasure Coding ähnlich wie in EIP4844, aber die polynomiale Erasure Coding in EIP4844 wird auf 2D RS Erasure Coding aktualisiert und die Speichersicherheit wird erneut verbessert, so dass nur 25 % Brüche erforderlich sind, um die gesamten Transaktionsdaten wiederherzustellen. Im Wesentlichen handelt es sich nur um eine kostengünstige öffentliche POS-Kette, und wenn Sie das Problem der historischen Datenspeicherung von Ethereum lösen möchten, benötigen Sie viele andere spezifische Module, um mit Celestia zu arbeiten. In Bezug auf Rollups ist zum Beispiel Sovereign Rollup einer der am meisten empfohlenen Rollup-Modi auf der offiziellen Website von Celestia. Anders als bei den üblichen Rollups auf Layer 2 wird nur die Transaktion berechnet und verifiziert, d. h., der Vorgang der Ausführungsschicht wird abgeschlossen. Sovereign Rollup umfasst den gesamten Ausführungs- und Abwicklungsprozess, wodurch die Verarbeitung von Transaktionen auf Celestia minimiert wird, was die Sicherheit des gesamten Transaktionsprozesses maximieren kann, wenn die Gesamtsicherheit von Celestia schwächer ist als die von Ethereum. Um die Sicherheit der von Celestia im Ethereum-Mainnet abgerufenen Daten zu gewährleisten, ist die gängigste Lösung der Quantum Gravity Bridge Smart Contract. Für Daten, die auf Celestia gespeichert sind, generiert es eine Merkle-Wurzel (Proof of Data Availability) und verbleibt auf dem Quantengravitationsbrückenvertrag im Ethereum-Mainnet, und jedes Mal, wenn Ethereum historische Daten auf Celestia aufruft, vergleicht es sein Hash-Ergebnis mit Merkle Root, und wenn dies der Fall ist, bedeutet dies, dass es sich tatsächlich um echte historische Daten handelt.
4.2.3 Öffentliche Kette DA speichern
In Bezug auf das Prinzip der DA-Technologie der Hauptkette sind viele Sharding-ähnliche Technologien aus der öffentlichen Speicherkette entlehnt. Unter den DAs von Drittanbietern haben einige von ihnen einige Speicheraufgaben direkt mit Hilfe der öffentlichen Speicherkette erledigt, z. B. werden die spezifischen Transaktionsdaten in Celestia im LL-IPFS-Netzwerk abgelegt. In der DA-Lösung eines Drittanbieters besteht neben dem Aufbau einer separaten öffentlichen Kette zur Lösung des Speicherproblems von Schicht 1 eine direktere Möglichkeit darin, die öffentliche Speicherkette direkt mit Schicht 1 zu verbinden, um die riesigen historischen Daten auf Schicht 1 zu speichern. Bei Hochleistungs-Blockchains ist das Volumen der historischen Daten noch größer, und die Datengröße der leistungsstarken öffentlichen Kette Solana liegt bei voller Geschwindigkeit bei fast 4 PG, was völlig außerhalb des Speicherbereichs gewöhnlicher Knoten liegt. Die von Solana gewählte Lösung bestand darin, historische Daten auf Arweave, einem dezentralen Speichernetzwerk, zu speichern und die Daten nur 2 Tage lang auf Knoten im Mainnet zur Überprüfung aufzubewahren. Um die Sicherheit des gespeicherten Prozesses zu gewährleisten, haben Solana und die Arweave-Kette ein Speicherbrückenprotokoll entwickelt, Solar Bridge. Die vom Solana-Knoten verifizierten Daten werden mit Arweave synchronisiert und das entsprechende Tag wird zurückgegeben. Mit diesem Tag können Solana-Nodes jederzeit die historischen Daten der Solana-Blockchain einsehen. Bei Arweave ist es nicht notwendig, dass die Knoten im gesamten Netzwerk die Datenkonsistenz aufrechterhalten und diese als Schwellenwert verwenden, um am Betrieb des Netzwerks teilzunehmen, sondern es wird stattdessen die Methode der Belohnungsspeicherung angewendet. Zunächst einmal verwendet Arweave keine traditionelle Kettenstruktur, um Blöcke zu bilden, sondern eher eine Graphenstruktur. In Arweave zeigt ein neuer Block nicht nur auf den vorherigen Block, sondern auch auf einen zufällig generierten Recall-Block. Die genaue Position eines Recall-Blocks wird durch den Hash seines vorherigen Blocks und seine Blockhöhe bestimmt, und die Position des Recall-Blocks ist unbekannt, bis der vorherige Block abgebaut wurde. Bei der Generierung neuer Blöcke müssen die Nodes jedoch über die Daten von Recall Block verfügen, um den POW-Mechanismus zur Berechnung des Hashs der angegebenen Schwierigkeit zu verwenden, und nur die Miner, die zuerst den Hash berechnen, der der Schwierigkeit entspricht, können belohnt werden, was die Miner dazu ermutigt, so viele historische Daten wie möglich zu speichern. Gleichzeitig gilt: Je weniger Personen einen historischen Block speichern, desto weniger Konkurrenten hat der Knoten bei der Generierung einer Difficulty Nonce, was Miner dazu ermutigt, Blöcke mit weniger Backups im Netzwerk zu speichern. Um sicherzustellen, dass Nodes dauerhaft Daten in Arweave speichern können, wird schließlich der Node-Scoring-Mechanismus von WildFire eingeführt. Knoten neigen dazu, mit Knoten zu kommunizieren, die schneller mehr historische Daten liefern können, während Knoten mit niedrigeren Bewertungen oft gar keinen Zugriff auf die neuesten Block- und Transaktionsdaten haben, so dass sie im Wettbewerb um POW nicht die Führung übernehmen können.
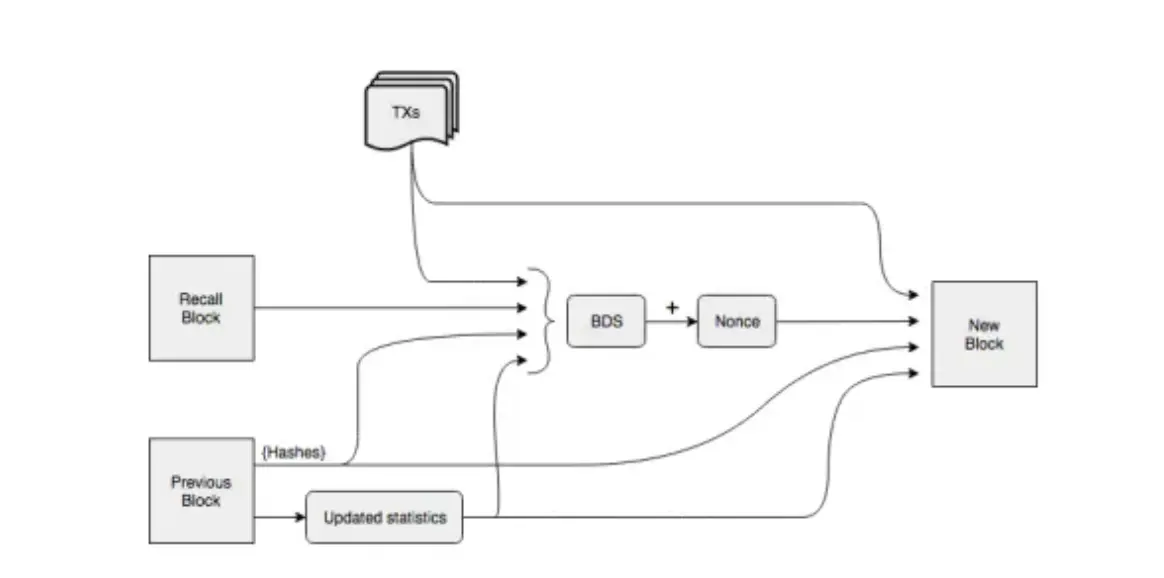
Wie Arweave-Blöcke gebaut werden, Bildquelle: Arweave Yellow-Paper
5. Umfassender Vergleich
Als Nächstes vergleichen wir die Vor- und Nachteile der einzelnen fünf Speicherszenarien basierend auf den vier Dimensionen der DA-Leistungsmetriken.
Sicherheit: Die größte Quelle für Datensicherheitsprobleme sind die Verluste, die durch Datenübertragung und böswillige Manipulation von unehrlichen Knoten verursacht werden, und im Cross-Chain-Prozess ist es aufgrund der Unabhängigkeit und des Zustands der beiden öffentlichen Chains, die nicht geteilt werden, der am stärksten betroffene Bereich der Datenübertragungssicherheit. Darüber hinaus hat Layer 1, der in dieser Phase eine dedizierte DA-Schicht erfordert, oft eine starke Konsensgruppe, und seine eigene Sicherheit ist viel höher als die von gewöhnlichen öffentlichen Speicherketten. Daher hat das Schema der Hauptkette DA eine höhere Sicherheit. Nachdem die Sicherheit der Datenübertragung sichergestellt wurde, geht es im nächsten Schritt darum, die Sicherheit der Gesprächsdaten zu gewährleisten. Wenn nur die kurzfristigen historischen Daten berücksichtigt werden, die zur Überprüfung von Transaktionen verwendet werden, werden dieselben Daten vom gesamten Netzwerk im temporär gespeicherten Netzwerk gesichert, während die durchschnittliche Anzahl der Datensicherungen im DankSharding-ähnlichen Schema nur 1/N der Anzahl der Knoten im gesamten Netzwerk beträgt, kann mehr Datenredundanz die Wahrscheinlichkeit verringern, dass die Daten verloren gehen, und kann auch mehr Referenzstichproben für die Überprüfung bereitstellen. Daher bietet die temporäre Speicherung eine höhere Datensicherheit. Im DA-Schema eines Drittanbieters verwendet der dedizierte DA der Hauptkette gemeinsame Knoten mit der Hauptkette, und Daten können während des Cross-Chain-Prozesses direkt über diese Relay-Knoten übertragen werden, so dass er auch eine relativ höhere Sicherheit als andere DA-Lösungen bietet.
Speicherkosten: Der größte Beitrag zu den Speicherkosten ist die Redundanz der Daten. In der Kurzzeitspeicherlösung der Hauptkette DA wird die Datensynchronisierung der Knoten des gesamten Netzwerks für die Speicherung verwendet, und alle neu gespeicherten Daten müssen von den Knoten des gesamten Netzwerks gesichert werden, was die höchsten Speicherkosten hat. Die hohen Speicherkosten wiederum führen dazu, dass diese Methode nur für die temporäre Speicherung in Netzwerken mit hoher TPS geeignet ist. Die zweite ist die Speichermethode von Sharding, einschließlich Sharding in der Hauptkette und Sharding in DAs von Drittanbietern. Da die Hauptkette tendenziell mehr Knoten hat, gibt es mehr Backups für jeden Block, sodass die Sharding-Lösung der Hauptkette höhere Kosten verursacht. Die niedrigsten Speicherkosten sind die öffentliche Speicherketten-DA, die die Belohnungsspeichermethode anwendet, und der Umfang der Datenredundanz in diesem Schema schwankt oft um eine feste Konstante. Gleichzeitig wurde auch ein dynamischer Anpassungsmechanismus in der öffentlichen Speicherkette DA eingeführt, um Knoten dazu zu bringen, weniger Backup-Daten zu speichern, indem die Belohnungen erhöht werden, um die Datensicherheit zu gewährleisten.
Datenlesegeschwindigkeit: Die Speichergeschwindigkeit von Daten wird hauptsächlich durch den Speicherort der Daten im Speicherplatz, den Datenindexpfad und die Verteilung der Daten in den Knoten beeinflusst. Unter anderem hat der Ort, an dem die Daten auf dem Knoten gespeichert werden, einen größeren Einfluss auf die Geschwindigkeit, da das Speichern der Daten im Arbeitsspeicher oder auf der SSD dazu führen kann, dass die Lesegeschwindigkeit um das Zehnfache variiert. Die öffentliche Speicherkette DA verwendet meist SSD-Speicher, da die Last auf der Kette nicht nur die Daten der DA-Schicht umfasst, sondern auch die persönlichen Daten mit hoher Speicherbelegung wie Videos und Bilder, die von Benutzern hochgeladen wurden. Wenn das Netzwerk keine SSDs als Speicherplatz nutzt, ist es schwierig, dem enormen Speicherdruck standzuhalten und die Anforderungen der Langzeitspeicherung zu erfüllen. Zweitens muss der Drittanbieter-DA bei Drittanbieter-DAs und Main-Chain-DAs, die In-Memory-Speicherdaten verwenden, zuerst nach den entsprechenden Indexdaten in der Hauptkette suchen und dann die Indexdaten über die Kette hinweg an den Drittanbieter-DA übertragen und die Daten über die Speicherbrücke zurückgeben. Im Gegensatz dazu können Mainchain-DAs Daten direkt von Knoten abfragen und haben daher schnellere Datenabrufgeschwindigkeiten. Schließlich muss die Sharding-Methode innerhalb der DA-Hauptkette den Block von mehreren Knoten aus aufrufen und die ursprünglichen Daten wiederherstellen. Daher ist die kurzfristige Speicherung langsamer als die kurzfristige Speicherung ohne Sharding.
DA-Layer-Universalität: Die DA-Universalität der Hauptkette geht gegen Null, da es unmöglich ist, Daten von einer öffentlichen Kette mit unzureichendem Speicherplatz auf eine andere öffentliche Kette mit unzureichendem Speicherplatz zu übertragen. Bei DAs von Drittanbietern sind die Vielseitigkeit der Lösung und ihre Kompatibilität mit einer bestimmten Hauptkette ein Paar widersprüchlicher Indikatoren. Zum Beispiel wurden in einem Mainchain-spezifischen DA-Schema, das für eine bestimmte Hauptkette entwickelt wurde, eine große Anzahl von Verbesserungen auf der Ebene des Knotentyps und des Netzwerkkonsenses vorgenommen, um sich an die öffentliche Kette anzupassen, so dass diese Verbesserungen ein großes Hindernis bei der Kommunikation mit anderen öffentlichen Ketten darstellen können. Innerhalb des Drittanbieter-DA ist der Speicher-Public-Chain-DA jedoch im Vergleich zum modularen DA in Bezug auf die Vielseitigkeit besser. Die öffentliche Speicherkette DA verfügt über eine größere Entwicklergemeinschaft und mehr Erweiterungsmöglichkeiten, die sich an die Situation verschiedener öffentlicher Ketten anpassen können. Gleichzeitig erhält die öffentliche Speicherkette DA Daten aktiver durch Paketerfassung, anstatt passiv Informationen zu empfangen, die von anderen öffentlichen Ketten übertragen werden. Daher kann es Daten auf seine eigene Weise kodieren, die standardisierte Speicherung von Datenflüssen realisieren, die Verwaltung von Dateninformationen aus verschiedenen Hauptketten erleichtern und die Speichereffizienz verbessern.
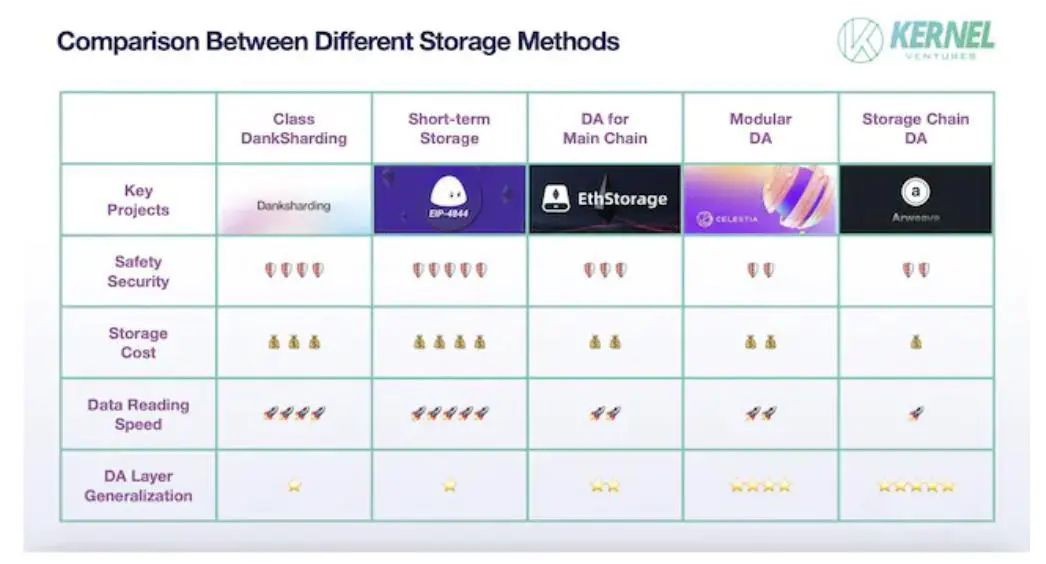
Vergleich der Leistung von Speicherlösungen, Bildquelle: Kernel Ventures
6. Zusammenfassung
Blockchains durchlaufen in dieser Phase einen Übergang von Krypto zu einem inklusiveren Web3, das mehr als nur eine Fülle von Projekten auf der Blockchain mit sich bringt. Um so viele Projekte, die gleichzeitig auf Layer 1 laufen, unterzubringen und gleichzeitig die Erfahrung von Gamefi- und Socialfi-Projekten zu gewährleisten, hat Layer 1, vertreten durch Ethereum, Methoden wie Rollups und Blobs zur Verbesserung von TPS eingeführt. Unter den entstehenden Blockchains wächst auch die Zahl der Hochleistungs-Blockchains. Eine höhere TPS bedeutet jedoch nicht nur eine höhere Leistung, sondern auch einen höheren Speicherdruck im Netzwerk. Für die massiven historischen Daten wird in dieser Phase eine Vielzahl von DA-Methoden vorgeschlagen, die auf der Hauptkette und Dritten basieren, um sich an das Wachstum des On-Chain-Speicherdrucks anzupassen. Jede Verbesserungsmethode hat Vor- und Nachteile, und sie ist in verschiedenen Kontexten unterschiedlich anwendbar.
Zahlungsbasierte Blockchains haben extrem hohe Anforderungen an die Sicherheit historischer Daten und verfolgen keine besonders hohen TPS. Wenn sich diese Art von öffentlicher Kette noch in der Vorbereitungsphase befindet, können Sie eine DankSharding-ähnliche Speichermethode einführen, die eine enorme Steigerung der Speicherkapazität bei gleichzeitiger Gewährleistung der Sicherheit erreichen kann. Wenn es sich jedoch um eine öffentliche Chain wie Bitcoin handelt, die gebildet wurde und über eine große Anzahl von Knoten verfügt, besteht ein großes Risiko, voreilige Verbesserungen auf der Konsensebene vorzunehmen, so dass es möglich ist, einen dedizierten DA für die Hauptkette mit hoher Sicherheit bei der Off-Chain-Speicherung einzuführen, um Sicherheits- und Speicherprobleme zu berücksichtigen. Es ist jedoch erwähnenswert, dass die Funktionalität der Blockchain nicht statisch ist, sondern sich ständig ändert. In den Anfängen beschränkten sich die Funktionen von Ethereum hauptsächlich auf Zahlungen und die Verwendung von Smart Contracts, um Vermögenswerte und Transaktionen einfach zu automatisieren, aber mit der kontinuierlichen Erweiterung des Blockchain-Territoriums wurden nach und nach verschiedene Socialfi- und Defi-Projekte zu Ethereum hinzugefügt, wodurch sich Ethereum in eine umfassendere Richtung entwickelte. Vor kurzem, mit dem Ausbruch der Inschriftenökologie auf Bitcoin, ist die Transaktionsgebühr des Bitcoin-Netzwerks seit August um fast das 20-fache gestiegen, was darauf zurückzuführen ist, dass die Transaktionsgeschwindigkeit des Bitcoin-Netzwerks in dieser Phase die Transaktionsnachfrage nicht befriedigen kann und Händler die Transaktionsgebühr nur erhöhen können, damit die Transaktion so schnell wie möglich verarbeitet werden kann. Jetzt muss die Bitcoin-Community einen Kompromiss eingehen, ob sie hohe Gebühren und langsame Transaktionsgeschwindigkeiten akzeptiert oder die Netzwerksicherheit reduziert, um die Transaktionsgeschwindigkeit zu erhöhen, aber dem ursprünglichen Zweck des Zahlungssystems zuwiderläuft. Entscheidet sich die Bitcoin-Community für Letzteres, dann muss angesichts des steigenden Datendrucks auch das entsprechende Speicherschema angepasst werden.
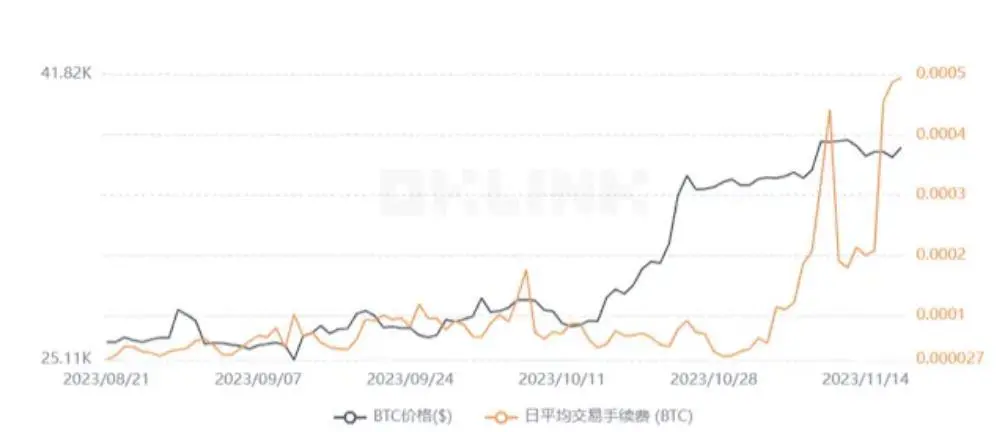
Die Transaktionsgebühren im Bitcoin-Mainnet schwanken, Bildquelle: OKLINK
Für die öffentliche Kette mit umfassenden Funktionen hat sie ein höheres Streben nach TPS, und das Wachstum historischer Daten ist noch größer, und es ist schwierig, sich langfristig an das schnelle Wachstum von TPS anzupassen, indem man eine DankSharding-ähnliche Lösung einführt. Daher ist es sinnvoller, die Daten zur Speicherung auf einen Drittanbieter-DA zu migrieren. Unter ihnen hat der DA, der für die Hauptkette bestimmt ist, die höchste Kompatibilität und kann vorteilhafter sein, wenn nur das Speicherproblem einer einzigen öffentlichen Kette berücksichtigt wird. In der heutigen öffentlichen Layer1-Chain sind jedoch auch der kettenübergreifende Asset-Transfer und die Dateninteraktion zu einem gemeinsamen Bestreben der Blockchain-Community geworden. Wenn wir die langfristige Entwicklung des gesamten Blockchain-Ökosystems betrachten, kann die Speicherung der historischen Daten verschiedener öffentlicher Ketten auf derselben öffentlichen Kette viele Sicherheitsprobleme im Datenaustausch- und Verifizierungsprozess beseitigen, so dass der Weg des modularen DA und der Speicherung des öffentlichen Chain-DA möglicherweise die bessere Wahl ist. Unter der Prämisse einer engen Universalität konzentriert sich die modulare DA auf die Bereitstellung von Diensten der DA-Schicht der Blockchain und führt verfeinerte historische Daten für die Indexdatenverwaltung ein, die eine vernünftige Klassifizierung von Daten verschiedener öffentlicher Ketten vornehmen kann und im Vergleich zur Speicherung öffentlicher Ketten mehr Vorteile bietet. Das obige Schema berücksichtigt jedoch nicht die Kosten für die Anpassung der Konsensschicht auf der bestehenden öffentlichen Kette, was äußerst riskant ist, und sobald es ein Problem gibt, kann es zu systemischen Schwachstellen führen und dazu führen, dass die öffentliche Kette den Konsens der Gemeinschaft verliert. Wenn es sich also um eine Übergangslösung im Prozess der Blockchain-Skalierung handelt, kann die einfachste Zwischenspeicherung der Hauptkette besser geeignet sein. Schließlich basieren die obigen Diskussionen auf der Leistung im tatsächlichen Betriebsprozess, aber wenn das Ziel einer öffentlichen Kette darin besteht, ihre eigene Ökologie zu entwickeln und mehr Projektbeteiligte und -teilnehmer anzuziehen, kann sie auch Projekte bevorzugen, die von ihrer eigenen Stiftung unterstützt und finanziert werden. Zum Beispiel wird die Ethereum-Community bei gleicher oder sogar etwas geringerer Gesamtleistung als das öffentliche Chain-Speicherschema EthStorage auch als Layer2-Projekt bevorzugen, das von der Ethereum Foundation unterstützt wird, um das Ethereum-Ökosystem weiterzuentwickeln.
Alles in allem bringt die zunehmende Komplexität der heutigen Blockchains auch einen höheren Speicherplatzbedarf mit sich. Wenn genügend Layer-1-Validatoren vorhanden sind, müssen die historischen Daten nicht von allen Knoten im gesamten Netzwerk gesichert werden, sondern nur bis zu einer bestimmten Anzahl, um eine relative Sicherheit zu gewährleisten. Gleichzeitig wird die Arbeitsteilung der öffentlichen Ketten immer detaillierter, wobei Layer 1 für Konsens und Ausführung zuständig ist, Rollup für Berechnung und Verifizierung zuständig ist und dann eine separate Blockchain für die Datenspeicherung verwendet. Jedes Teil kann sich auf eine Funktion konzentrieren, ohne durch die Leistung der anderen eingeschränkt zu werden. Wie viel oder wie viel Prozent der Knoten historische Daten speichern müssen, um ein Gleichgewicht zwischen Sicherheit und Effizienz zu erreichen, und wie die sichere Interoperabilität zwischen verschiedenen Blockchains gewährleistet werden kann, ist jedoch eine Frage, über die Blockchain-Entwickler nachdenken und die sie ständig verbessern müssen. Investoren können auf das DA-Projekt der Hauptkette auf Ethereum achten, da Ethereum zu diesem Zeitpunkt bereits genügend Unterstützer hat, so dass es nicht auf andere Communities angewiesen ist, um seinen Einfluss auszuweiten. Es besteht mehr Bedarf, ihre eigenen Gemeinschaften zu verbessern und zu entwickeln und mehr Projekte für das Ethereum-Ökosystem zu gewinnen. Für öffentliche Chains in der Position von Verfolgern, wie Solana und Aptos, verfügt die einzelne Chain selbst jedoch nicht über ein so vollständiges Ökosystem, so dass sie eher geneigt sein könnte, die Kräfte anderer Gemeinschaften zu vereinen, um ein riesiges Cross-Chain-Ökosystem aufzubauen, um ihren Einfluss zu erweitern. Daher verdienen generische DAs von Drittanbietern für die aufkommende Schicht 1 mehr Aufmerksamkeit.