Первоисточник: Heart of the Machine
 Источник изображения: Generated by Unbounded AI
Источник изображения: Generated by Unbounded AI
Искусственный интеллект стремительно развивается, но проблем много. Новый API зрения GPT от OpenAI заставляет людей вздыхать, что передняя нога очень эффективна, а задняя нога жалуется на проблему иллюзии.
Галлюцинации всегда были фатальным недостатком больших моделей. Из-за большого и сложного набора данных в нем неизбежно будет содержаться устаревшая и неверная информация, что приведет к серьезной проверке качества вывода. Слишком большое количество повторяющейся информации также может привести к смещению больших моделей, что также является формой иллюзии. Но галлюцинации не являются неразрешимыми. Тщательное использование и строгая фильтрация наборов данных в процессе разработки, а также построение высококачественных наборов данных, а также оптимизация структуры модели и методов обучения могут в определенной степени смягчить проблему иллюзий.
В моде так много больших моделей, и насколько они эффективны в облегчении галлюцинаций? Вот таблица лидеров, которая четко контрастирует с разрывом.
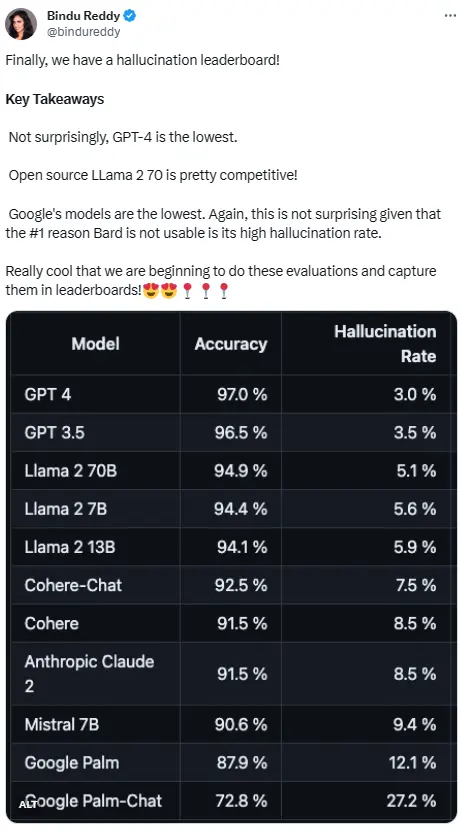 Таблица лидеров публикуется платформой Vectara, ориентированной на искусственный интеллект. Таблица лидеров была обновлена 1 ноября 2023 года, и Vectara заявила, что продолжит следить за оценками галлюцинаций по мере обновления модели.
Таблица лидеров публикуется платформой Vectara, ориентированной на искусственный интеллект. Таблица лидеров была обновлена 1 ноября 2023 года, и Vectara заявила, что продолжит следить за оценками галлюцинаций по мере обновления модели.
Адрес проекта:
Чтобы определить эту таблицу лидеров, компания Vectara провела исследование фактической согласованности сводной модели с использованием различных наборов данных с открытым исходным кодом и обучила модель обнаруживать галлюцинации в выходных данных LLM. Они использовали SOTA-подобную модель, а затем передали 1000 коротких документов каждому из этих LLM через публичный API и попросили их обобщить каждый документ, используя только факты, представленные в документе. Из этих 1000 документов только 831 был обобщен каждой моделью, а остальные были отвергнуты по крайней мере одной моделью из-за ограничений по содержанию. Используя эти 831 файл, Вектара вычислил общую точность и частоту галлюцинаций для каждой модели. Процент отклонения ответов для каждой модели подробно описан в столбце «Процент ответов». Ни одно из содержимого, отправляемого в модель, не содержит нелегального или небезопасного содержимого, но слов-триггеров в нем достаточно для срабатывания некоторых фильтров содержимого. Эти документы в основном взяты из корпуса CNN/Daily Mail.
 Важно отметить, что Vectara оценивает краткую точность, а не общую фактическую точность. Это позволяет сравнить реакцию модели на предоставленную информацию. Другими словами, выходная сводка оценивается как «фактически согласованная», как и исходный документ. Поскольку неизвестно, на каких данных обучается каждый магистр права, невозможно определить галлюцинации для какой-либо конкретной проблемы. Кроме того, чтобы построить модель, которая может определить, является ли ответ иллюзией без эталонного источника, необходимо решить проблему галлюцинаций, а также обучить модель, которая была бы такой же или большей, чем оцениваемый LLM. В результате, Вектара решил посмотреть на частоту галлюцинаций в суммарной задаче, так как такая аналогия была бы хорошим способом определить общую реалистичность модели.
Важно отметить, что Vectara оценивает краткую точность, а не общую фактическую точность. Это позволяет сравнить реакцию модели на предоставленную информацию. Другими словами, выходная сводка оценивается как «фактически согласованная», как и исходный документ. Поскольку неизвестно, на каких данных обучается каждый магистр права, невозможно определить галлюцинации для какой-либо конкретной проблемы. Кроме того, чтобы построить модель, которая может определить, является ли ответ иллюзией без эталонного источника, необходимо решить проблему галлюцинаций, а также обучить модель, которая была бы такой же или большей, чем оцениваемый LLM. В результате, Вектара решил посмотреть на частоту галлюцинаций в суммарной задаче, так как такая аналогия была бы хорошим способом определить общую реалистичность модели.
Адрес модели Detect Illusion:
Кроме того, LLM все чаще используются в конвейерах RAG (Retri Augmented Generation) для ответов на запросы пользователей, таких как интеграция Bing Chat и Google Chat. В системе RAG модель развертывается как агрегатор результатов поиска, поэтому таблица лидеров также является хорошим индикатором того, насколько точна модель при использовании в системе RAG.
Из-за неизменно превосходной производительности GPT-4, кажется, что он имеет самый низкий уровень галлюцинаций. Тем не менее, некоторые пользователи сети заявили, что он был удивлен тем, что GPT-3.5 и GPT-4 не очень далеки друг от друга.
 LLaMA 2 имеет лучшую производительность после GPT-4 и GPT-3.5. Но производительность большой модели Google действительно неудовлетворительна. Некоторые пользователи сети заявили, что Google BARD часто использует фразу «Я все еще тренируюсь», чтобы уклониться от своих неправильных ответов.
LLaMA 2 имеет лучшую производительность после GPT-4 и GPT-3.5. Но производительность большой модели Google действительно неудовлетворительна. Некоторые пользователи сети заявили, что Google BARD часто использует фразу «Я все еще тренируюсь», чтобы уклониться от своих неправильных ответов.
 С такой таблицей лидеров мы можем иметь более интуитивное суждение о преимуществах и недостатках различных моделей. Несколько дней назад OpenAI запустила GPT-4 Turbo, нет, некоторые пользователи сети сразу предложили обновить и его в таблице лидеров.
С такой таблицей лидеров мы можем иметь более интуитивное суждение о преимуществах и недостатках различных моделей. Несколько дней назад OpenAI запустила GPT-4 Turbo, нет, некоторые пользователи сети сразу предложили обновить и его в таблице лидеров.
 Посмотрим, как будет выглядеть следующий рейтинг, и будут ли в нем существенные изменения.
Посмотрим, как будет выглядеть следующий рейтинг, и будут ли в нем существенные изменения.
Ссылка:
Отказ от ответственности: Информация на этой странице может поступать от третьих лиц и не отражает взгляды или мнения Gate. Содержание, представленное на этой странице, предназначено исключительно для справки и не является финансовой, инвестиционной или юридической консультацией. Gate не гарантирует точность или полноту информации и не несет ответственности за любые убытки, возникшие от использования этой информации. Инвестиции в виртуальные активы несут высокие риски и подвержены значительной ценовой волатильности. Вы можете потерять весь инвестированный капитал. Пожалуйста, полностью понимайте соответствующие риски и принимайте разумные решения, исходя из собственного финансового положения и толерантности к риску. Для получения подробностей, пожалуйста, обратитесь к
Отказу от ответственности.
