Google Releases Gemini 3.1 Pro, ARC-AGI-2 Reasoning Benchmark Scores Double to 77.1%, Securing 13 Out of 16 Top Positions Across Benchmarks, API Pricing Unchanged, AI Arms Race Accelerates the Compression of Each Generation’s Lifecycle.
(Background: Gemini Launches Free “SAT Practice Tests,” AI Tutoring Offers Personalized Learning Guides)
(Additional Context: Google Officially Launches “Gemini 3”! Topping the World’s Smartest AI Models—What Are the Highlights?)
Table of Contents
- “Adjustable Reasoning”: Let Developers Decide How Smart the Model Is
- Same Price, Double Performance: Who Is Subsidizing This War?
- No Clear Winner-Takes-All, But a Clear Competitive Landscape
Last night (19th), Google officially released the Gemini 3.1 Pro preview, achieving a score of 77.1% on ARC-AGI-2 (a benchmark measuring a model’s logical reasoning ability to solve entirely new problems), more than doubling the previous Gemini 3 Pro score.
In the chart below, among the 16 benchmarks evaluated by Google, 3.1 Pro took first place in 13.
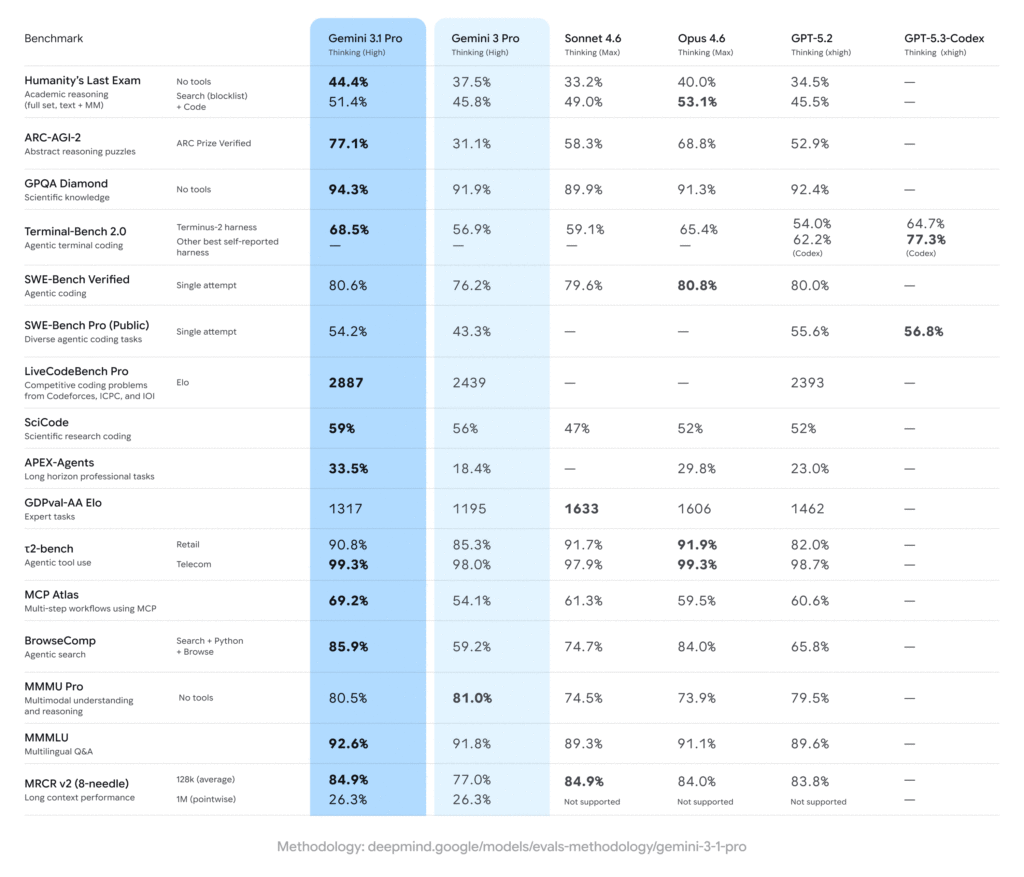
Other key scores are equally impressive: GPQA Diamond (expert-level scientific knowledge) 94.3%, SWE-Bench Verified (autonomous code repair) 80.6%, Humanity’s Last Exam 44.4%, MMMLU 92.6%.
On MCP Atlas (a benchmark measuring multi-step tool usage workflows), 3.1 Pro reached 69.2%, nearly 10 percentage points ahead of Claude and GPT-5.2.
“Adjustable Reasoning”: Let Developers Decide How Smart the Model Is
A strategically significant new feature of Gemini 3.1 Pro is the three-tier thinking depth system. Developers can toggle the model’s “reasoning budget” among low, medium, and high settings, using lower levels for simple API calls to save latency and cost, and switching to higher levels for complex debugging.
When set to high, 3.1 Pro’s behavior closely resembles a “mini” version of Google’s dedicated reasoning model Gemini Deep Think. VentureBeat described this as “Deep Think Mini activated on demand.”
On BrowseComp (a benchmark measuring AI agent’s autonomous web search ability), 3.1 Pro soared from 59.2% to 85.9%. An AI agent capable of searching the web, completing multi-step tasks, and significantly improving reasoning accuracy is exactly the direction the entire AI industry is betting on.
Same Price, Double Performance: Who Is Subsidizing This War?
API pricing remains at $2 per million input tokens and $12 per million output tokens, identical to Gemini 3 Pro. In terms of cost, Gemini 3.1 Pro’s input cost is 60% lower than Claude Opus 4.6, and output cost is 52% lower.
With doubled performance but unchanged pricing, Google is using a “cost-performance dominance” strategy to capture the developer market.
The context window remains at 1 million tokens (five times Claude’s, 2.5 times GPT-5), with output limits expanded from previous generations to 65,000 tokens. Single API upload limits increased from 20MB to 100MB, and it even supports directly inputting YouTube URLs for the model to “watch” videos.
Behind this price stability is Google’s structural cost advantage in developing its own TPU chips and cloud infrastructure. Google demonstrates that having its own chips is the biggest moat in the AI arms race.
No Clear Winner-Takes-All, But a Clear Competitive Landscape
Of course, Gemini 3.1 Pro isn’t the champion in every domain.
Claude Sonnet 4.6 (Thinking Max mode) ties with 3.1 Pro on long-context memory (MRCR v2), but significantly outperforms on GDPval-AA Elo expert tasks (1633 vs. 1317).
OpenAI’s GPT-5.3-Codex leads in terminal programming tasks (Terminal-Bench 2.0) with 77.3%, ahead of 3.1 Pro’s 68.5%. The hallucination rate of Claude series (~3%) is also notably lower than Gemini and GPT (average around 6%).
The AI competition landscape in 2026 is: Google leads in reasoning and agent tasks, Anthropic excels in accuracy and safety, and OpenAI maintains advantages in code generation and ecosystem. No single winner-takes-all, but the “shuffle” may happen every three months.
The AI arms race won’t stop. The only question is: who ultimately benefits from this competition—developers, platforms, or the biggest payers?
Google’s stance today is: make it affordable for developers first, then talk about everything else. This strategy worked once in the cloud era; whether it can work again depends on whether AI can truly create enough value for enterprises to recoup their investments, rather than just setting higher benchmark scores.

Disclaimer: The information on this page may come from third parties and does not represent the views or opinions of Gate. The content displayed on this page is for reference only and does not constitute any financial, investment, or legal advice. Gate does not guarantee the accuracy or completeness of the information and shall not be liable for any losses arising from the use of this information. Virtual asset investments carry high risks and are subject to significant price volatility. You may lose all of your invested principal. Please fully understand the relevant risks and make prudent decisions based on your own financial situation and risk tolerance. For details, please refer to
Disclaimer.
