Story so far
Zero-knowledge proofs (ZKPs) are becoming increasingly important for decentralized systems. ZK first came into the public eye for its success in projects such as ZCash, but today ZK is known as a scaling solution for Ethereum.
Leveraging ZK, Layer 2 (e.g. Scroll and Polygon), also known as Rollups, is developing zkEVMs (zk Ethereum Virtual Machine). These zkEVMs process a batch of transactions and generate a small proof (in kilobytes). This attestation can be used to verify to the entire network that the batch of transactions is valid and correct.
However, their uses don’t stop there. ZK allows for a variety of interesting applications.
Private Layer 1 – Mina, for example, hides the details of transactions and data on its blockchain, allowing users to only prove the validity of their transactions without revealing the specifics of the transaction itself. neptune.cash and Aleo are also very interesting projects.
Decentralized cloud platform - FedML and together.xyz allow machine learning (ML) models to be trained in a decentralized way, outsource computations to the network, and verify the correctness of computations using ZKP. Druglike is building a more open drug discovery platform using similar technologies.
Decentralized Storage - Filecoin is revolutionizing cloud storage, and ZK is at its core, allowing storage providers to prove that they have stored the right data over a period of time.
GAME - A more advanced version of Darkforest may appear, which requires real-time proof. ZK may also expand the game to reduce the likelihood of cheating. Maybe also work with a decentralized cloud platform to enable the game to pay for its own hosting!
Identity - Decentralized authentication is now also possible through ZK. Around this idea, a number of interesting projects are being built. For example, notebook and zkemail (recommended to learn about).
The impact of ZK and decentralized systems is huge, however, the development of the story is not perfect, and there are still many obstacles and challenges today. The process of including generating proofs is very resource-intensive and requires many complex mathematical operations. As developers seek to build more ambitious and complex protocols and systems using ZK technology, both for proof generation and verification processes, developers are demanding smaller proof sizes, faster performance, and better optimizations.
In this article, we’ll explore the current state of hardware acceleration and how it will play a key role in advancing ZK adoption.
Snark vs Stark
There are two popular zero-knowledge techniques today, zk-STARK and zk-SNARK (we have ignored Bulletproofs in this article).
|
|
|
| zk-STARK |
zk-SNARK |
|
| Complexity - Prover |
O(N * poly-log(N)) |
O(N * log(N)) |
| Complexity - Verifier |
O(poly-log(N)) |
O(1) |
| Proof size |
45KB-200KB |
~ 288 Bytes |
| 抗量子 |
Yes (hash function based) |
No |
| Trusted setup |
No |
Yes |
| Zero Knowledge |
Yes |
Yes |
| Interactivity |
Interactive or non-interactive |
Non interactive |
| Developer Documentation |
Limited, but expanding Good |
|
表1:Snark VS Stark
As mentioned above, there are differences and trade-offs between the two. The most important point is that the trusted setup of a zk-SNARK-based system relies on at least one honest participant involved in the trusted setup process and having their keys destroyed at the end of the process. In terms of on-chain verification, zk-SNARKs are much cheaper in terms of gas fees. In addition, the proofs of zk-SNARKs are also significantly smaller, making them cheaper to store on-chain.
Currently, zk-SNARKs are more popular than zk-STARKs. The most likely reason is that zk-SNARKs have a much longer history. Another possible reason is that Zcash, one of the first ZK blockchains, used zk-SNARKs, so most of the current development tools and documentation revolve around the zk-SNARK ecosystem.
How to build a ZK Application
Developers may need two components to complete the development of a ZK application
A ZK-friendly expression computation method (DSL or low-level library).
An attestation system that implements two functions: Prove and Verify.
DSLs (domain-specific language) and low-level libraries
When it comes to DSLs, there are a lot of options, such as Circom, Halo2, Noir, and many more. Circom is probably the most popular at the moment.
When it comes to low-level libraries, a popular example is Arkworks; There are also libraries in development, such as ICICLE, which is a CUDA acceleration library.
These DSLs are designed to output confined systems. Unlike the usual program, which is usually evaluated in the form of x:= y *z, the same program in the constrained form looks more like x-y * z = 0. By representing the program as a system of constraints, we find that operations such as addition or multiplication can be represented by a single constraint. However, more complex operations, such as bit operations, can require hundreds of constraints!
As a result, it becomes complicated to implement some hash functions as ZK-friendly programs. In zero-knowledge proofs, hash functions are often used to ensure the integrity of the data and/or to verify specific properties of the data, but due to the large number of constraints of bit operations, some hash functions are difficult to adapt to the environment of zero-knowledge proofs. This complexity may affect the efficiency of proof generation and verification, and thus become a problem that developers need to consider and solve when building ZK-based applications
As a result, it becomes complicated to implement some hash functions to be ZK-friendly.
Proving
A proof system can be likened to a piece of software that accomplishes two main tasks: generating proofs and verifying proofs. Proof systems typically accept circuitry, evidence, and public/private parameters as inputs.
The two most popular proof systems are the Groth16 and PLONK series (Plonk, HyperPlonk, UltraPlonk)
|
|
|
|
|
|
|
Trusted Setup |
Proof size |
Prover Complexity |
Verifier Complexity |
Flexibility |
| Groth16 |
Circuit specific |
small |
Low |
Low |
Low |
| Plonk |
Universal |
Large |
High |
常数 |
High |
表2:Groth16 vs Plonk
As shown in Table 2, Groth16 requires a trusted setup process, but Groth16 provides us with faster proof and verification times, as well as a constant proof size.
Plonk provides a generic setup that performs a pre-processing phase for the circuit you are running every time a proof is generated. Despite supporting many circuits, Plonk’s verification time is constant.
There are also differences between the two in terms of constraints. Groth16 grows linearly in terms of constraint size and lacks flexibility, while Plonk is more flexible.
Overall, understand that performance is directly related to the number of constraints in your ZK application. The more constraints, the more operations the prover must compute.
bottleneck
The proof system consists of two main mathematical operations: multiscalar multiplication (MSM) and fast Fourier transform (FFT). Today we will explore systems where both exist, where MSM can take up about 60% of the runtime, while FFT can take up about 30%.
MSM requires a lot of memory access, which in most cases consumes a lot of memory on the machine, while also performing many scalar multiplication operations.
FFT algorithms often require rearranging the input data into a specific order to perform transformations. This can require a lot of data movement and can be a bottleneck, especially for large input sizes. Cache utilization can also be an issue if memory access patterns don’t fit into the cache hierarchy.
**In this case, hardware acceleration is the only way to fully optimize the performance of ZKP. **
Hardware Acceleration
When it comes to hardware acceleration, it reminds us of how ASICs and GPUs dominated Bitcoin and Ethereum mining.
While software optimizations are equally important and valuable, they have their limitations. Hardware optimization, on the other hand, can improve parallelism by designing FPGAs with multiple processing units, such as reducing thread synchronization or vectorization. Memory access can also be optimized more efficiently by improving memory hierarchies and access patterns.
Now in the ZKP space, the main trend seems to have shifted: GPUs and FPGAs.
In the short term, GPUs have an advantage in price, especially after ETH shifts to proof-of-stake (POS), leaving a large number of GPU miners idle and on standby. In addition, GPUs have the advantage of short development cycles and provide developers with a lot of “plug-and-play” parallelism.
However, FPGAs should catch up, especially when comparing form factors and power consumption. FPGAs also provide lower latency for high-speed data streams. When multiple FPGAs are clustered together, they provide better performance compared to GPU clusters.
GPU VS FPGA
GPU:
Development time: GPUs provide fast development time. Developer documentation for frameworks like CUDA and OpenCL is well-developed and popular.
Power consumption: GPUs are very “power-hungry”. Even when developers take advantage of data-level parallelism and thread-level parallelism, GPUs still consume a lot of power.
Availability: Consumer-grade GPUs are cheap and readily available right now.
FPGA:
Development cycle: FPGAs have a more complex development cycle and require more specialized engineers. FPGAs allow engineers to achieve many “low-level” optimizations that GPUs cannot.
Latency: FPGAs provide lower latency especially when processing large data streams.
Cost vs. Availability: FPGAs are more expensive than GPUs and are not as readily available as GPUs.
ZPRIZE
Nowadays, when it comes to the bottleneck of hardware optimization and ZKP, there is a competition that cannot be avoided - ZPRIZE
ZPrize is one of the most important initiatives in the ZK field right now. ZPrize is a competition that encourages teams to develop hardware acceleration for ZKP’s key bottlenecks (e.g., MSM, NTT, Poseidon, etc.) on multiple platforms (e.g., FPGAs, GPUs, mobile devices, and browsers) based on latency, throughput, and efficiency.
The result was very interesting. For example, the GPU improvements are huge:
MSM at 2^26 has increased by 131% from 5.86 seconds to 2.52 seconds. On the other hand, FPGA solutions tend not to have any benchmarks compared to GPU results, which have previous benchmarks to compare to, and most FPGA solutions are open-sourced for the first time with such algorithms expected to improve in the future.
These results indicate the direction that most developers feel comfortable in developing their hardware acceleration solutions. Many teams compete for the GPU category, but only a small percentage compete for the FPGA category. I’m not sure if it’s because of a lack of experience when developing for FPGAs, or if most FPGA companies/teams choose to develop secretly to sell their solutions commercially.
ZPrize has provided some very interesting research to the community. As more rounds of ZPrize begin, we will see more and more interesting solutions and problems appear.
Practical examples of hardware acceleration
Taking Groth16 as an example, if we examine the implementation of rapidsnark for Groth16, we can observe that two main operations are performed: FFT (Fast Fourier Transform) and MSM (Multiscalar Multiplication); These two basic operations are common in many proof systems. Their execution time is directly related to the number of constraints in the circuit. Naturally, the number of constraints increases as more complex circuits are written.
To get a sense of how computationally intensive FFT and MSM operations are, we can check out Ingonyama’s benchmark of the Groth16 circuit (Filecoin’s Vanilla C2 process performed on a 32GB sector), and the results are as follows
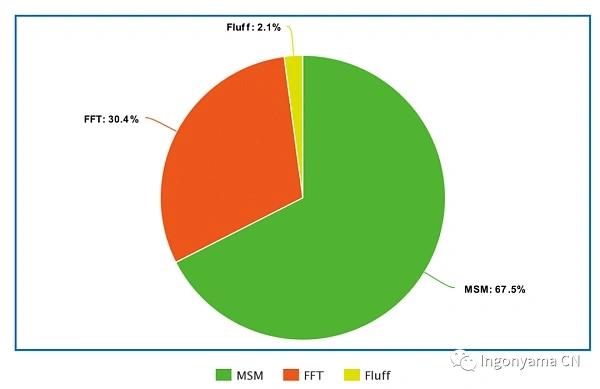
As shown in the figure above, MSM (Multiscalar Multiplication) can be time-consuming and a serious performance bottleneck for many provers, making MSM one of the most important cryptographic operators that need to be accelerated.
So how much computation does MSM occupy for the prover in other ZK proof systems? This is shown in the figure below

In Plonk, MSM accounts for more than 85% of the overhead, as shown in Ingonyama’s latest paper, Pipe MSM. **
So how should hardware acceleration speed up MSM? **
MSM
Before we talk about how to accelerate MSM, we need to understand what MSM is
Multi-Scalar Multiplication (MSM) is an algorithm for calculating the sum of multiple scalar multiplications in the following form

where G is a point in the elliptic curve group, a is a scalar, and the result of MSM will also be an elliptic curve point
We can decompose MSM into two main sub-components:
Modular Multiplication
Elliptic Curve Point Additions
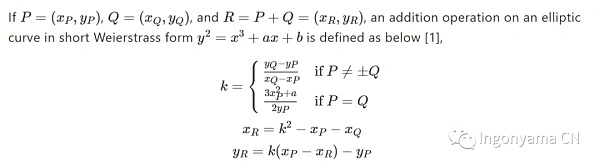
Let’s take Affine(x,y) as an example to perform a naïve P+Q operation.
When we want to calculate P + Q = R, we need to calculate a value k, by the abscissa of k and P,Q
Get the coordinates of R. The calculation process is as above, in this process we perform 2 times multiplication, 1 square operation, 1 inverse operation, and several times addition and subtraction operations. It is worth noting that the above operations are performed in a finite field, i.e. under mod P. In reality, P will be very large. **
The cost of the above operation is to find the inverse >> multiplication** **> **** squared, and the cost of addition and subtraction is negligible.
So we want to avoid inverses as much as possible, because the cost of a single inversion is at least a hundredfold of multiplication. We can do this by expanding the coordinate system, but at the cost of increasing the number of multiplications in the process, such as Jacobian coordinates: XYZ += XYZ, and multiplying more than 10 times, depending on the addition algorithm. **
GPU VS FPGA Accelerated MSM
This section compares two leading MSM implementations, PipeMSM and Sppark, where PipeMSM is implemented on FPGAs and Sppark is implemented on GPUs.
Sppark and PipeMSM use the state-of-the-art Pippenger algorithm to implement MSM, also known as the bucket algorithm; **
Sppark is implemented using CUDA; Their versions are highly parallelism and have achieved impressive results when running on the latest GPUs.
However, PipeMSM not only optimizes the algorithm, but also provides optimizations for the mathematical primitives of Modular Multiplication and EC Addition. PipeMSM handles the entire “MSM stack”, implementing a series of mathematical tricks and optimizations aimed at making MSM more suitable for hardware, and designing a hardware design designed to reduce latency with a focus on parallelization.
Let’s take a quick recap of the PipeMSM implementation.
Low Latency
PipeMSM is designed to provide low latency when executing multiple MSMs on a large number of inputs. GPUs don’t offer deterministic low latency due to dynamic frequency scaling, and GPUs adjust their clock speeds based on workloads.
But thanks to the optimized hardware design, FPGA implementations can provide deterministic performance and latency for specific workloads.
EC Addition Implementation
The Elliptic Curve Point Addition (EC Addition) is implemented as a low-latency, highly parallel, and complete formula (complete means that it correctly calculates the sum of any two points in the elliptic curve group). Elliptic curve point addition is used in a pipelined manner in the EC addition module to reduce latency.
We chose to represent the coordinates as projective coordinates, and on the addition algorithm we use a Complete elliptic curve point addition formula. The main advantage is that we don’t have to deal with edge cases. Complete formulas;
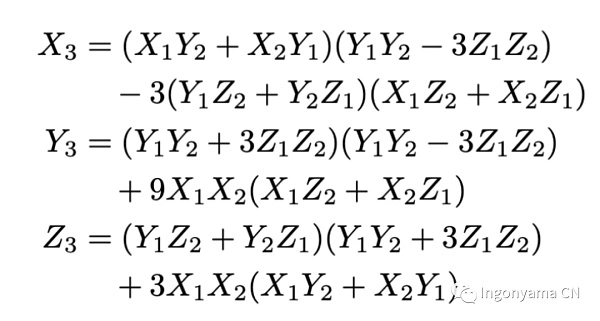
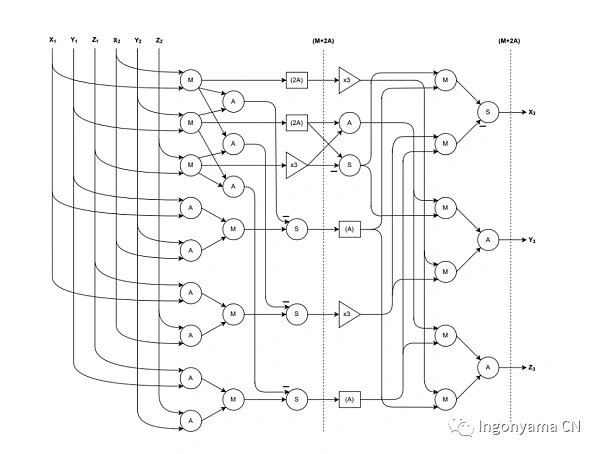
We implemented this addition formula in a pipelined and parallel fashion, and our FPGA elliptic curve adder circuit only needed 12 multiplications, 17 sums of additions, and this formula was executed. The original formula requires 15 modulo multiplication and 13 additions. The FPGA design is as follows
Multi mod
We made use of the Barrett Reduction and Karatsuba algorithms.
Barrett Reduction is an algorithm that efficiently calculates r≡ab mod p (where p is fixed). Barrett Reduction attempts to replace division (an expensive operation) by approximate division. An error tolerance can be selected to describe the range within which we are looking for the correct result. We find that the large error tolerance allows for the use of smaller reduction constants; This reduces the size of the intermediate values used in modulo reduction operations, which reduces the number of multiplications required to calculate the final result.
In the blue box below, we can see that due to our high error tolerance, we have to perform multiple checks to find an accurate result.
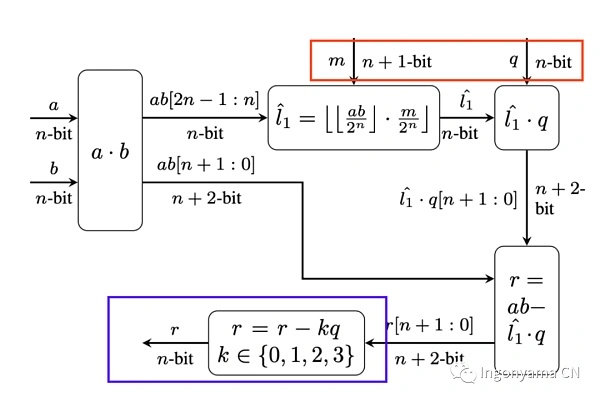
In a nutshell, the Karatsuba algorithm is used to optimize the multiplication we perform in Barrett Reduction. Karatsuba’s algorithm simplifies the multiplication of two n-digits to the multiplication of three n/2-digits; These multiplications can simplify the number of digits to be narrow enough to be directly computed by hardware. Details can be read in Ingo’s paper: Pipe MSM
Using the above operators, we have developed a low-latency, highly parallel MSM implementation.
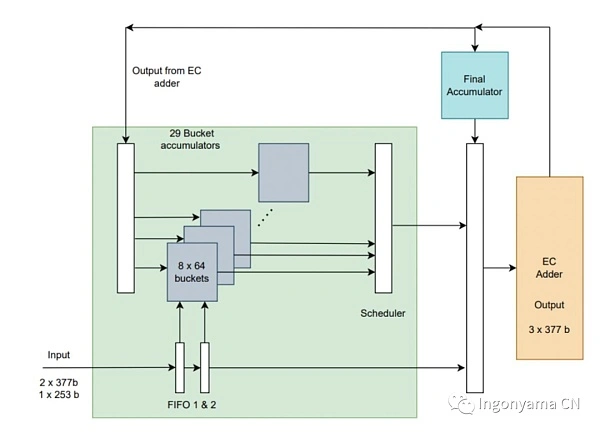
The core idea is that instead of computing the entire MSM at once, each chunk is passed into the EC adder in parallel. The results of the EC adder are accumulated into the final MSM.
End Result****
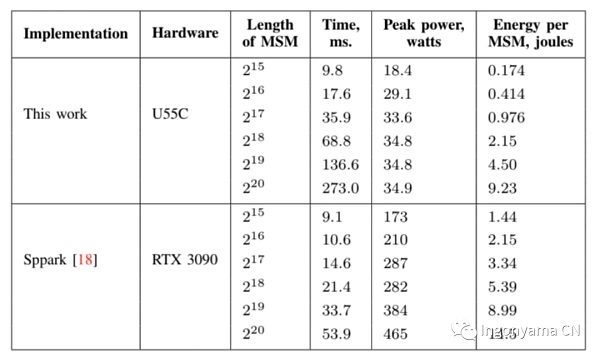
The diagram above shows the comparison between Sppark and PipeMSM.
Most prominently is the significant energy savings offered by FPGAs, which could be extremely important for future large-scale proof generation operations. It’s worth noting that our implementation was prototyped and benchmarked under @125MHz, and increasing the clock speed to @500MHz could increase the computation time by 4x or more.
Another advantage of using our FPGAs is that they can be installed in small chassis servers because they consume less energy and generate less heat.
We are in the early stages of FPGA engineering for ZKP and should expect further improvements in the algorithms. In addition, the FPGA is computing the MSM while the CPU is idle, and it may be possible to achieve faster times by using the FPGA in combination with the system resources (CPU/GPU).
Summary
ZKP has become a key technology for distributed systems.
The application of ZKP will go far beyond just extending the Ethereum level, allowing the outsourcing of computation to untrusted third parties, allowing the development of previously impossible systems, such as distributed cloud computing, identity systems, and more.
Traditionally, ZKP optimizations have focused on software-level improvements, but as the demand for more superior performance increases, we will see more advanced acceleration solutions involving both hardware and software.
At present, the acceleration solutions we see mainly use GPUs, because the development time using CUDA is short, and the current consumer GPUs are very cheap and abundant. The GPU also offers incredible performance. So GPUs are unlikely to disappear from this space anytime soon.
As more complex development teams enter the space, it’s likely that we’ll see FPGAs leading the way in terms of power efficiency and performance. Compared to GPUs, FPGAs offer more low-level customization as well as more configuration options. FPGAs offer faster development speed and flexibility than ASICs. With the rapid development of the ZKP world, FPGAs can be reflashed with different programs to accommodate different systems and update solutions.
However, to generate near real-time proofs, it may be necessary to combine GPU/FPGA/ASIC configurations depending on the system for which we generate proofs.
ZPU is also likely to evolve to provide extremely efficient solutions for large-scale proof generators and low-power devices (see previous article for details).