Want to make money with large models? This powerful new face decided to bring down the cost of reasoning first.
Original source: Heart of the Machine
 Image source: Generated by Unbounded AI
Image source: Generated by Unbounded AI
How much money does the large-scale model business burn? Some time ago, a report in the Wall Street Journal gave a reference answer.
According to the report, Microsoft’s GitHub Copilot business (backed by OpenAI’s GPT model) charges $10 per month, but it still costs an average of $20 per user. AI service providers are facing significant economic challenges – these services are not only expensive to build, but also very expensive to operate.
Someone likened it to “using AI to summarize an email is like asking a Lamborghini to deliver a pizza.”
OpenAI has calculated a more detailed account of this: when the context length is 8K, the cost of every 1K input token is 3 cents, and the cost of output is 6 cents. Currently, OpenAI has 180 million users and receives more than 10 million queries per day. In this way, in order to operate a model like ChatGPT, OpenAI needs to invest about $7 million a day in the necessary computing hardware, which can be said to be frighteningly expensive.
 Reducing the cost of inference for LLMs is imperative, and increasing inference speed is a proven critical path. **
Reducing the cost of inference for LLMs is imperative, and increasing inference speed is a proven critical path. **
In fact, the research community has proposed a number of technologies to accelerate LLM inference tasks, including DeepSpeed, FlexGen, vLLM, OpenPPL, FlashDecoding, and TensorRT-LLM. Naturally, these technologies also have their own advantages and disadvantages. Among them, FlashDecoding is a state-of-the-art method proposed by FlashAttention authors and Tri Dao et al. from the Stanford University team last month, which greatly improves the inference speed of LLMs by loading data in parallel, and is considered to have great potential. But at the same time, it introduces some unnecessary computational overhead, so there’s still a lot of room for optimization.
To further solve the problem, a joint team from Infinigence-AI, Tsinghua University, and Shanghai Jiao Tong University recently proposed a new method, FlashDecoding++, which not only brings more acceleration than the previous method (can speed up GPU inference by 2-4x), but more importantly, supports both NVIDIA and AMD GPUs! Its core idea is to achieve true parallelism in attention computation through an asynchronous approach, and to accelerate computation in the Decode stage for “chunky” matrix product optimization. **
 Address:
Address:
Accelerates GPU inference by 2-4x,
How does FlashDecoding++ do it? **
The LLM inference task is generally to input a piece of text (token), and continue to generate text or other forms of content through LLM model calculation.
The inference computation of LLM can be divided into two stages: Prefill and Decode, where the Prefill stage generates the first token by understanding the input text; In the Decode phase, subsequent tokens are output sequentially. In the two stages, the computation of LLM inference can be divided into two main parts: attention computation and matrix multiplication computation.
For attention computing, existing work, such as FlashDecoding, implements parallel loading of data with the softmax operator in sharding attention computing. This method introduces 20% computational overhead in attention calculations due to the need to synchronize the maximum values in different parts of softmax. For matrix multiplication calculations, in the Decode stage, left-multiplication matrices mostly appear as “chunky” matrices, that is, the number of rows is generally not large (e.g., <=8), and the existing LLM inference engine expands the number of rows to 64 by complementing 0 to accelerate it by architecture such as Tensor Cores, resulting in a large number of invalid computations (multiplied by 0).
In order to solve the above problems, the core idea of “FlashDecoding++” is to realize the true parallelism of attention computation through asynchronous methods, and accelerate the computation in the Decode stage for the “Humpty Dumpty” matrix multiplication optimization. **
Asynchronous Parallel Partial Softmax Calculations
 *Figure 1 Asynchronous Parallel Section Softmax Computation
*Figure 1 Asynchronous Parallel Section Softmax Computation
The previous work entered the maximum value for each part of the softmax calculation as the scale factor to avoid the overflow of the e exponent in the softmax calculation, which resulted in the synchronization overhead of the different parts of the softmax calculation (Figure 1(a)(b)).
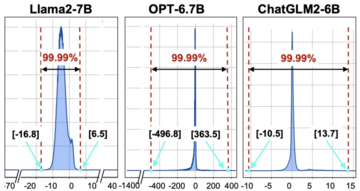 Figure 2 Statistical Distribution of Softmax Input Values
Figure 2 Statistical Distribution of Softmax Input Values
“FlashDecoding++” points out that for most LLMs, the softmax input distribution is more concentrated. As shown in Figure 2, more than 99.99% of the softmax input for Llama2-7B is concentrated in the range [-16.8, 6.5]. Therefore, “FlashDecoding++” proposes to use a fixed maximum value for some softmax calculations (Fig. 1 ©), thus avoiding frequent synchronization between different softmax calculations. When the input with a small probability is outside the given range, the softmax calculation of this part of “FlashDecoding++” degenerates to the original calculation method.
Humpty Dumpty Matrix Product Optimization
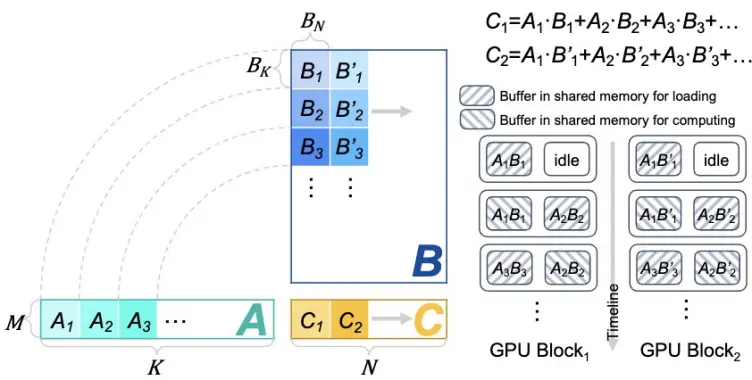 Fig.3 Humpty Dumpty Matrix Multiplication Sharding and Dual Caching Mechanism
Fig.3 Humpty Dumpty Matrix Multiplication Sharding and Dual Caching Mechanism
Since the input to the Decode stage is one or several token vectors, the matrix product for that stage behaves in a “chunky” shape. Take the matrix A×B=C as an example, where the shape of the A and B matrices is M×K and K×N, and the “Humpty Dumpty” matrix multiplies M when M is smaller. “FlashDecoding++” points out that the “Humpty Dumpty” matrix is limited by the general cache, and proposes optimization methods such as the double cache mechanism to accelerate it (Fig. 3).
 Figure 4 Adaptive Matrix Multiplication Implementation
Figure 4 Adaptive Matrix Multiplication Implementation
In addition, “FlashDecoding++” further points out that in the LLM inference stage, the values of N and K are fixed for a specific model. Therefore, “FlashDecoding++” adaptively selects the optimal implementation of the matrix product according to the magnitude of M.
Speeds up GPU inference by 2-4x
 Fig. 5 “FlashDecoding++” NVIDIA vs. AMD platform LLM inference (Llama2-7B model, batchsize=1)
Fig. 5 “FlashDecoding++” NVIDIA vs. AMD platform LLM inference (Llama2-7B model, batchsize=1)
Currently, FlashDecoding++ can accelerate LLM inference on the backend of multiple GPUs, such as NVIDIA and AMD (Figure 5). By speeding up the generation of the first token in the Prefill phase and the generation speed of each token in the Decode phase, “FlashDecoding++” can accelerate the generation of both long and short texts. **FlashDecoding++ accelerates inference by an average of 37% on NVIDIA A100 compared to FlashDecoding, and up to 2-4x faster than Hugging Face on NVIDIA and AMD’s multi-GPU backends. **
AI Large Model Entrepreneurship Rookie: Wuwen Core Dome
The three co-authors of the study are Dr. Dai Guohao, chief scientist of Wuwen Core Dome and associate professor of Shanghai Jiao Tong University, Hong Ke, research intern of Wuwen Core Dome and master’s student of Tsinghua University, and Xu Jiaming, research intern of Wuwen Core Dome and doctoral student of Shanghai Jiao Tong University. The corresponding authors are Professor Dai Guohao of Shanghai Jiao Tong University and Professor Wang Yu, Dean of the Department of Electronic Engineering of Tsinghua University.
Founded in May 2023, the goal is to create the best solution for the integration of software and hardware for large models, and FlashDecoding++ has been integrated into the large model computing engine “Infini-ACC”. With the support of “Infini-ACC”, Wuwen Core Dome is developing a series of large-scale software and hardware integration solutions, including large-scale model "Infini-Megrez", software and hardware all-in-one machine, etc.
It is understood that “Infini-Megrez” has performed very well in handling long texts, increasing the length of the text that can be processed to a record-breaking 256k token**, and the actual processing of about 400,000 words of the entire “Three-Body Problem 3: Death Eternal” is not a problem. This is the longest text length that can be processed by a large model today.
 In addition, the “Infini-Megrez” large model has achieved first-tier algorithm performance on datasets such as C (MEDIUM), MMLU (ENGLISH), CMMLU (medium), and AGI, and is continuously evolving based on the “Infini-ACC” computing engine.
In addition, the “Infini-Megrez” large model has achieved first-tier algorithm performance on datasets such as C (MEDIUM), MMLU (ENGLISH), CMMLU (medium), and AGI, and is continuously evolving based on the “Infini-ACC” computing engine.