作者:CJ_Blockchain
Ngày 3 tháng 2 năm 2025, một mẫu DeepSeek-R1 đã âm thầm ra mắt trên nền tảng Internet siêu máy tính quốc gia.
Trong vòng một tháng sau đó, nhờ hiệu năng trực tiếp đối đầu các mô hình độc quyền hàng đầu và chi phí huấn luyện rẻ như “bắp cải”, nó đã lan tỏa khắp toàn cầu.
Gây ra sự sụt giảm mạnh của các cổ phiếu AI trên thị trường Mỹ và mở ra “Khoảnh khắc DeepSeek” của AI Trung Quốc.
Ngày 10 tháng 3 năm 2026, Subnet 3 Templar của Bittensor thông báo đã hoàn thành quá trình huấn luyện trước mô hình ngôn ngữ lớn (LLM) phi tập trung lớn nhất lịch sử — Covenant-72B
Đây là quá trình huấn luyện trước mô hình ngôn ngữ lớn phi tập trung lớn nhất lịch sử:
72 tỷ tham số, trên bộ dữ liệu khoảng 1.1 nghìn tỷ token, hoàn toàn thực hiện qua mạng của Bittensor Subnet 3, không cần phép, hơn 70 nút độc lập tham gia tự do.
Bittensor đã bước vào Khoảnh khắc DeepSeek của riêng mình.
1. Templar (SN3): Chuyển đổi mô hình từ thu thập dữ liệu đến huấn luyện cốt lõi
Tiền thân của Templar là SN3 do Omega Labs vận hành, ban đầu tập trung vào thu thập và khai thác dữ liệu đa phương thức. Với sự tiến bộ của cơ chế Bittensor, subnet này đã thực hiện bước chuyển chiến lược từ “người vận chuyển dữ liệu” sang “thợ đúc mô hình”.
Hiện tại, Templar định vị là hạ tầng huấn luyện mô hình phân tán toàn cầu. Nó tập hợp sức mạnh tính toán dị hợp toàn cầu qua cơ chế khuyến khích, nhằm giải quyết chi phí tính toán cực kỳ đắt đỏ trong huấn luyện mô hình lớn và vấn đề kiểm duyệt tập trung. Việc giao hàng thành công Covenant-72B đã chứng minh độ trưởng thành của mô hình sản xuất phi tập trung này.
2. Covenant-72B: Phá vỡ giới hạn quy mô của huấn luyện phi tập trung
Covenant-72B là thành quả mang tính bước ngoặt của Templar, đồng thời là mô hình huấn luyện trước kiến trúc dày đặc lớn nhất trong mạng phi tập trung hiện nay.
- Tham số chính: 720 tỷ tham số, dựa trên bộ dữ liệu DCLM hiệu suất cao để huấn luyện trước.
- Hiệu suất đối đầu: Trong đánh giá mô hình cơ bản, hiệu suất gần như tương đương với Llama-2-70B của Meta.
- Tối ưu lệnh: Covenant-72B-Chat sau tinh chỉnh thể hiện sức cạnh tranh mạnh mẽ trong các lĩnh vực IFEval (tuân thủ lệnh) và MATH (suy luận toán học), thậm chí vượt qua các mô hình độc quyền cùng quy mô trong một số chỉ số.
- Hiệu quả suy luận: Mô hình đạt tốc độ xử lý 450 tokens/sec, giải quyết điểm nghẽn phản hồi chậm trong ứng dụng thực tế của mô hình lớn.
3. Thuật toán SparseLoCo: Động cơ nền tảng của huấn luyện phi tập trung
Trong môi trường internet thông thường, thách thức lớn nhất khi huấn luyện mô hình 72B là băng thông liên nút. Templar đã sử dụng thuật toán cốt lõi SparseLoCo để đạt bước đột phá:
- Nén cực độ: Thuật toán chỉ truyền 1%-3% các thành phần gradient cốt lõi, lượng dữ liệu được lượng hóa thành 2-bit, giảm đáng kể yêu cầu băng thông mạng.
- Đồng bộ tần suất thấp: Không giống như đồng bộ từng bước của các cụm truyền thống, SparseLoCo cho phép các nút thực hiện 15-250 vòng lặp cục bộ trước khi đồng bộ toàn cục.
- Bù lỗi: Thông qua cơ chế cộng dồn gradient cục bộ, đảm bảo độ chính xác hội tụ của mô hình ngay cả khi mất hơn 97% thông tin.
Cách tiếp cận công nghệ này chứng minh rằng: ngay cả không có các cụm mạng đắt tiền như InfiniBand, dựa vào mạng phân tán toàn cầu thông thường vẫn có thể tạo ra trí tuệ đỉnh cao.
4. Đánh giá ngành và phản ứng thị trường
Thành tựu công nghệ của Templar đã thu hút sự chú ý của giới AI chính thống và thị trường vốn:
Jack Clark, đồng sáng lập của Anthropic, trong báo cáo phân tích đã xếp Templar vào hàng mạng huấn luyện phi tập trung lớn nhất thế giới đang hoạt động, và cho biết tốc độ phát triển vượt quá dự đoán của ngành.
Jason Calacanis (Chủ podcast All-In, nhà đầu tư nổi tiếng Silicon Valley) đã giới thiệu sâu về cơ chế của Bittensor trong blog gần đây, và ngầm gợi ý mọi người mua.
Grayscale liên tục tăng cổ phần TAO, xem đó là vị trí cốt lõi trong lĩnh vực AI phi tập trung.
DCG thành lập Yuma, tập trung thúc đẩy hệ sinh thái Bittensor (TAO), được xem là cược lớn nhất và trực tiếp nhất của DCG vào AI phi tập trung.
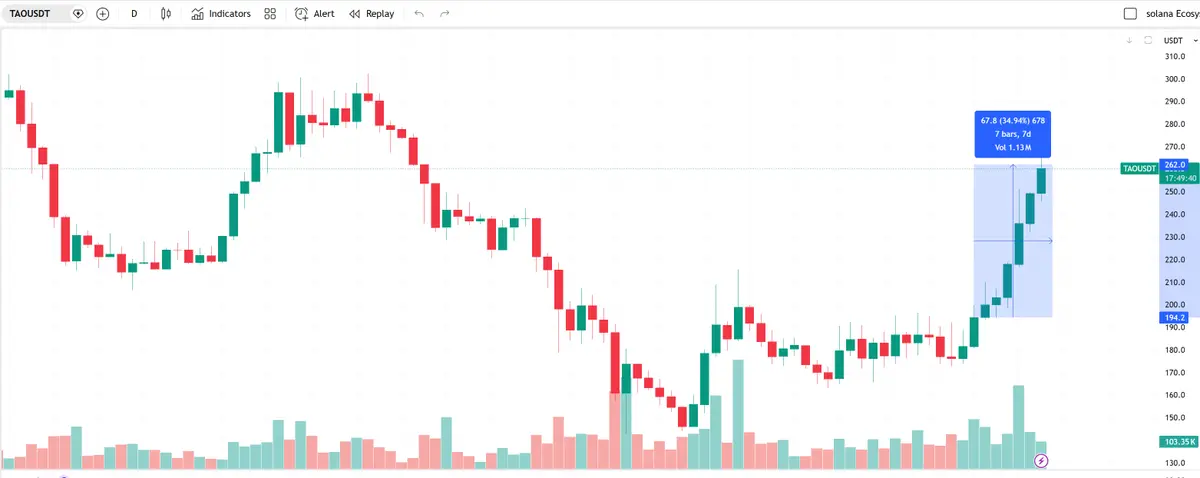
$TAO: Sau khi Templar công bố hoàn thành huấn luyện mô hình 72B, TAO đã tăng hơn 30%, thể hiện sức mạnh rõ rệt trong bối cảnh biến động của BTC.
$Templar (SN-3): Templar tăng 75% trong 7 ngày, được gọi là “rồng” trong việc thu hút phát thải của Bittensor hiện tại. Vốn hóa thị trường hiện chỉ 70 triệu USD.
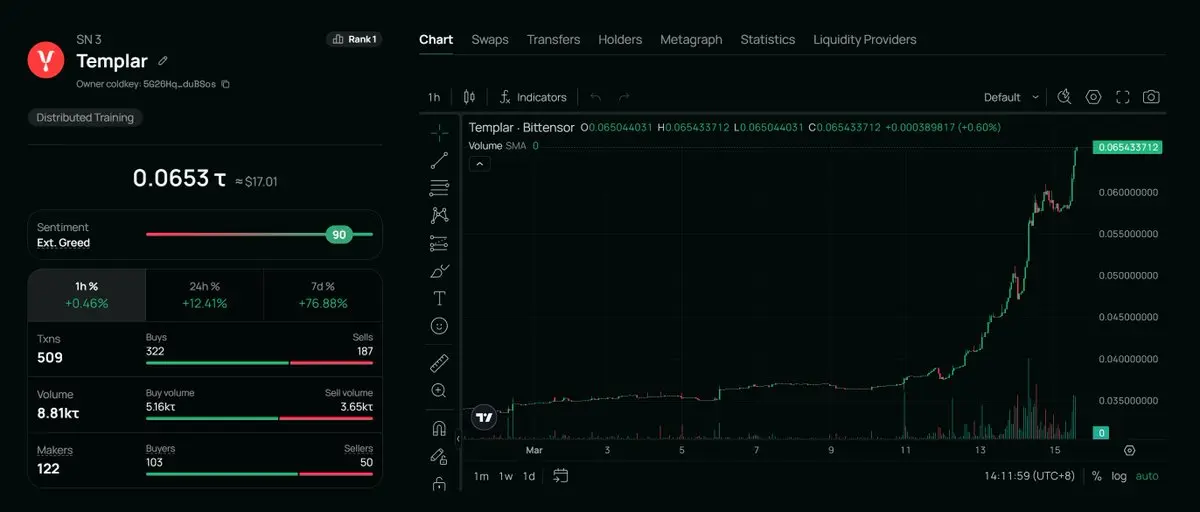
5. Tiềm năng đầu tư subnet và giới hạn hệ sinh thái
Thành công của Templar mở ra không gian tưởng tượng mới cho hệ sinh thái Bittensor:
- Mở rộng giới hạn giá trị: Trong thời gian dài, giới đã nghi ngờ Bittensor chỉ là “khuyến khích không khí”. Templar chứng minh rằng giao thức này có thể tạo ra công cụ sản xuất có khả năng cạnh tranh thương mại, chuyển đổi định hướng định giá TAO từ “kể chuyện” sang “sản phẩm”.
- Tiềm năng của sức mạnh tính toán dị hợp: Với sự phát triển của “SparseLoCo dị hợp”, card đồ họa tiêu dùng như RTX 4090 có thể trực tiếp tham gia huấn luyện các mô hình hàng trăm tỷ tham số, thúc đẩy bình đẳng hóa nguồn lực tính toán.
- Cơ hội xác định của subnet: Trong cơ chế dTAO, các subnet như Templar có công nghệ cốt lõi, liên tục tạo ra mô hình hiệu suất cao, token của chúng có giá trị dài hạn rất cao.
Templar hiện có MC=75 triệu USD, FDV=350 triệu USD
Trong khi các công ty mô hình lớn chính thống như OpenAI định giá 840 tỷ USD, Anthropic 350 tỷ USD, Minimax 45 tỷ USD.
Không nhất thiết Templar có thể so sánh trực tiếp với các công ty này, nhưng trong bối cảnh hiện tại, khi các câu chuyện thiếu hụt, sự chú ý phân tán và người ta không còn tin vào phi tập trung, sự xuất hiện của Templar chắc chắn là liều thuốc tinh thần mạnh mẽ cho AI phi tập trung.
Kết luận
Templar chứng minh rằng môi trường phi tập trung không chỉ lưu trữ dữ liệu mà còn có thể sản xuất trí tuệ. Covenant-72B chỉ là bước khởi đầu, khi kết hợp theo chiều dọc SN3 (huấn luyện trước), SN39 (tính toán) và SN81 (học tăng cường), một hình thái của OpenAI phi tập trung chạy trên blockchain đã dần hình thành.
Ngành Crypto từ khi ra đời đến nay đã phủ nhận vô số câu chuyện, các dự án lưu trữ phi tập trung, tính toán phi tập trung, máy tính phi tập trung từng gây sốt giờ đã có vẻ như bị phủ nhận, nhưng vẫn có những dự án kiên trì tiến bước trên con đường phi tập trung và đạt thành tựu.
Thành công của Templar không chỉ là Khoảnh khắc DeepSeek của Bittensor, mà còn có thể là Khoảnh khắc DeepSeek của Crypto.
Tuyên bố miễn trừ trách nhiệm: Thông tin trên trang này có thể đến từ bên thứ ba và không đại diện cho quan điểm hoặc ý kiến của Gate. Nội dung hiển thị trên trang này chỉ mang tính chất tham khảo và không cấu thành bất kỳ lời khuyên tài chính, đầu tư hoặc pháp lý nào. Gate không đảm bảo tính chính xác hoặc đầy đủ của thông tin và sẽ không chịu trách nhiệm cho bất kỳ tổn thất nào phát sinh từ việc sử dụng thông tin này. Đầu tư vào tài sản ảo tiềm ẩn rủi ro cao và chịu biến động giá đáng kể. Bạn có thể mất toàn bộ vốn đầu tư. Vui lòng hiểu rõ các rủi ro liên quan và đưa ra quyết định thận trọng dựa trên tình hình tài chính và khả năng chấp nhận rủi ro của riêng bạn. Để biết thêm chi tiết, vui lòng tham khảo
Tuyên bố miễn trừ trách nhiệm.
