Tóm tắt ngắn gọn
- Microsoft đã phát hành hai chế độ khác nhau để ghép GPT và Claude nhằm nâng cao chất lượng nghiên cứu AI.
- Critique khiến các mô hình cộng tác, trong khi Council cho chúng làm việc song song, còn một thẩm định viên thứ ba tìm ra các điểm khác biệt.
- Quy trình với hai mô hình này khắc phục tình trạng bịa đặt, trích dẫn yếu và các vấn đề khác liên quan đến nghiên cứu AI chỉ dùng một mô hình.
AI nghiên cứu chuyên sâu (Deep research) đã là một trong những cuộc chạy đua nóng nhất trong công nghệ năm nay. Google đã công bố tác nhân nghiên cứu của họ cho Gemini vào tháng 12 năm 2024, OpenAI ra mắt tác nhân nghiên cứu của riêng mình vào tháng 2 năm 2025, xAI cũng làm theo, Perplexity thì ra sức đầu tư thêm, và Claude của Anthropic đã xây dựng được lượng người theo dõi trung thành trong giới chuyên nghiệp cần các câu trả lời chi tiết, có trích dẫn, đồng thời giới thiệu tác nhân của mình vào tháng 4 năm ngoái.
Mọi công ty đều đang cố thuyết phục bạn rằng mô hình AI đơn lẻ của họ là nhà nghiên cứu thông minh nhất trong căn phòng. Microsoft vừa nói: Tại sao phải chọn chỉ một?
Công ty công bố hai tính năng mới vào thứ Hai cho công cụ Researcher của Copilot—gọi là Critique và Council—đưa GPT của OpenAI và Claude của Anthropic vào làm việc trên cùng một nhiệm vụ nghiên cứu theo chuỗi. Kết quả, theo bài kiểm tra của Microsoft đối chiếu với một chuẩn benchmark trong ngành, đạt điểm cao hơn mọi hệ thống nằm trong bài thử nghiệm đó, bao gồm cả các mô hình từ những công ty AI hàng đầu.
Giới thiệu Critique, một hệ thống nghiên cứu chuyên sâu đa mô hình mới trong M365 Copilot.
Bạn có thể sử dụng nhiều mô hình cùng nhau để tạo ra các phản hồi và báo cáo tối ưu. pic.twitter.com/m4RlQmCKzs
— Satya Nadella (@satyanadella) March 30, 2026
“Critique là một hệ thống nghiên cứu chuyên sâu đa mô hình mới được thiết kế cho các tác vụ nghiên cứu phức tạp. Nó tách quá trình tạo sinh khỏi khâu đánh giá và sử dụng kết hợp các mô hình từ các phòng thí nghiệm Frontier, bao gồm Anthropic và OpenAI”, Microsoft giải thích. “Một mô hình dẫn dắt giai đoạn tạo sinh—lập kế hoạch cho nhiệm vụ, lặp qua quá trình truy xuất, và tạo bản nháp ban đầu—trong khi mô hình thứ hai tập trung vào phần rà soát và tinh chỉnh, đóng vai trò như một nhà đánh giá chuyên môn trước khi báo cáo cuối cùng được tạo ra.”
Vấn đề cơ bản mà Critique được thiết kế để khắc phục là như sau: Mọi công cụ nghiên cứu AI hiện nay đều hoạt động theo cùng một cách. Bạn đặt một câu hỏi, một mô hình lập kế hoạch tìm kiếm, lục lọi nguồn, viết một báo cáo rồi trả lại cho bạn. Mô hình đơn lẻ đó làm mọi thứ mà không có ai kiểm tra công việc của nó.
Điều này có thể dẫn đến một số thông tin bịa đặt lọt vào, một số lỗi trong trích dẫn, các tuyên bố giả hoặc không chính xác, v.v.
Critique phá vỡ quy trình đó thành hai phần. GPT xử lý giai đoạn đầu—lập kế hoạch nghiên cứu, trích xuất nguồn, và viết một bản nháp ban đầu. Sau đó Claude bước vào như một biên tập viên nghiêm ngặt, rà soát báo cáo về độ chính xác của dữ kiện, chất lượng trích dẫn, và liệu câu trả lời có thực sự giải quyết đúng điều được hỏi hay không. Chỉ sau phần rà soát này thì báo cáo cuối cùng mới đến tay người dùng. Microsoft cho biết các vai trò này về sau cũng có thể chạy theo chiều ngược lại—Claude phác thảo và GPT đưa ra đánh giá—nhưng hiện tại thì GPT đi trước.
Trên benchmark DRACO—một bài kiểm tra chuẩn hóa bao phủ 100 tác vụ nghiên cứu phức tạp trên 10 lĩnh vực bao gồm y học, luật và công nghệ—Copilot với Critique đạt 57.4 điểm, trong khi Claude Opus của Anthropic tự thân đạt 42.7. Hệ thống kết hợp của Microsoft vượt kết quả tốt nhất tiếp theo gần 14%.
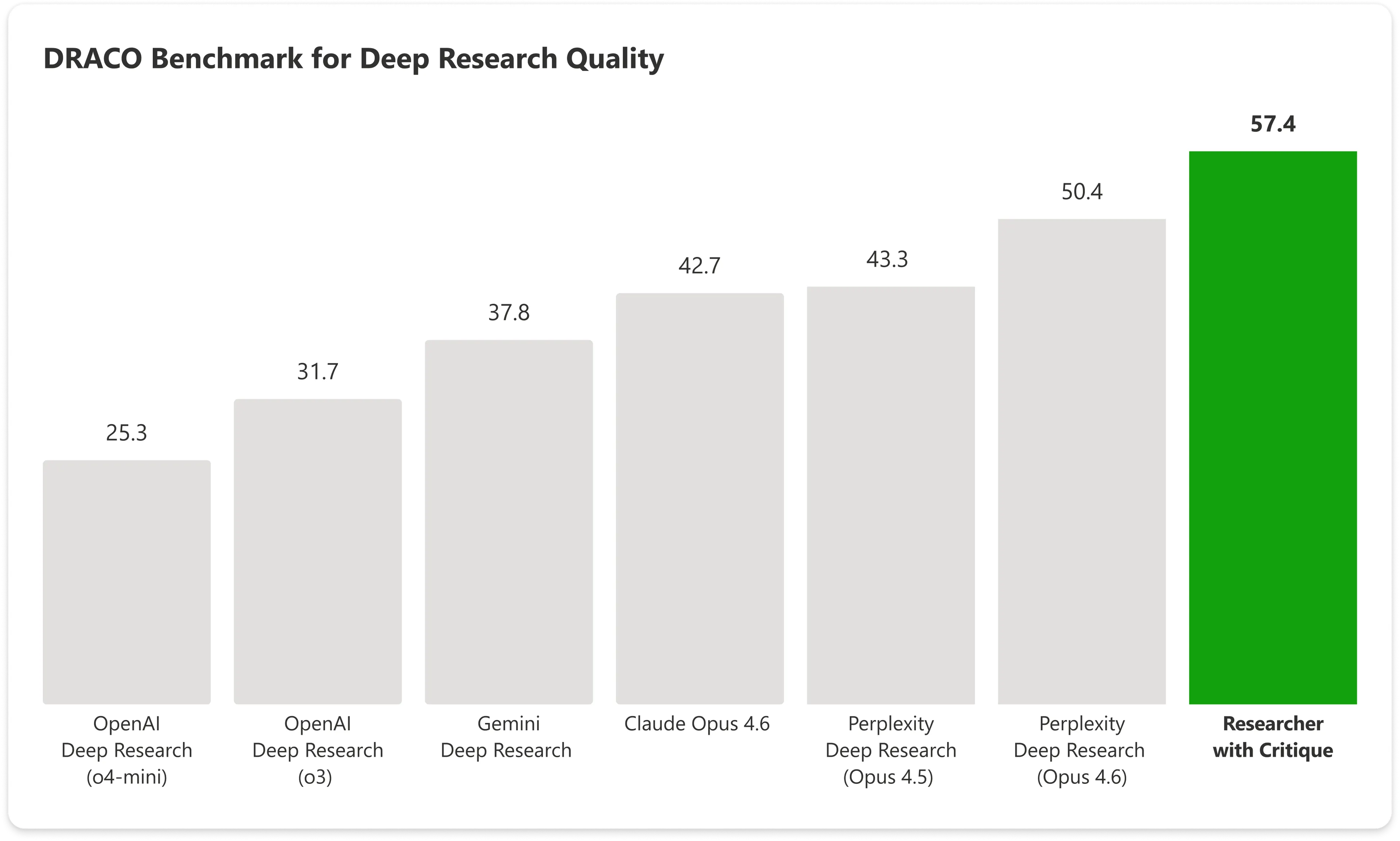
Image: Microsoft
Những cải thiện lớn nhất xuất hiện ở bề rộng phân tích và chất lượng trình bày, đồng thời độ chính xác về mặt dữ kiện cũng cho thấy một mức tăng đáng kể.
Tính năng thứ hai, Council, tiếp cận theo một hướng khác với cùng một vấn đề. Thay vì để một mô hình rà soát công việc của mô hình kia, Council chạy GPT và Claude đồng thời và đặt toàn bộ báo cáo của chúng cạnh nhau. Sau đó, một mô hình “thẩm phán” thứ ba đọc cả hai và viết một bản tóm tắt giải thích hai AI đã thống nhất ở đâu, khác nhau ở đâu, và mỗi bên đã bắt được góc nhìn độc đáo nào mà bên kia bỏ lỡ. So sánh các công cụ nghiên cứu AI một cách thủ công là điều mà người dùng trước đây phải tự làm.
Trong Critique, các mô hình về cơ bản cộng tác với nhau, trong khi ở Council thì các mô hình cạnh tranh với nhau.
Critique là trải nghiệm mặc định trong Researcher, còn Council yêu cầu bạn chọn “Model Council” từ bộ chọn để kích hoạt chế độ hiển thị song song. Cả hai tính năng hiện đang có sẵn cho người dùng đã đăng ký chương trình Frontier của Microsoft, kênh truy cập sớm cho những năng lực mới nhất của Copilot. Cần có giấy phép Microsoft 365 Copilot ($30/user/tháng), nhưng người dùng cũng phải được đăng ký Frontier để truy cập chúng.
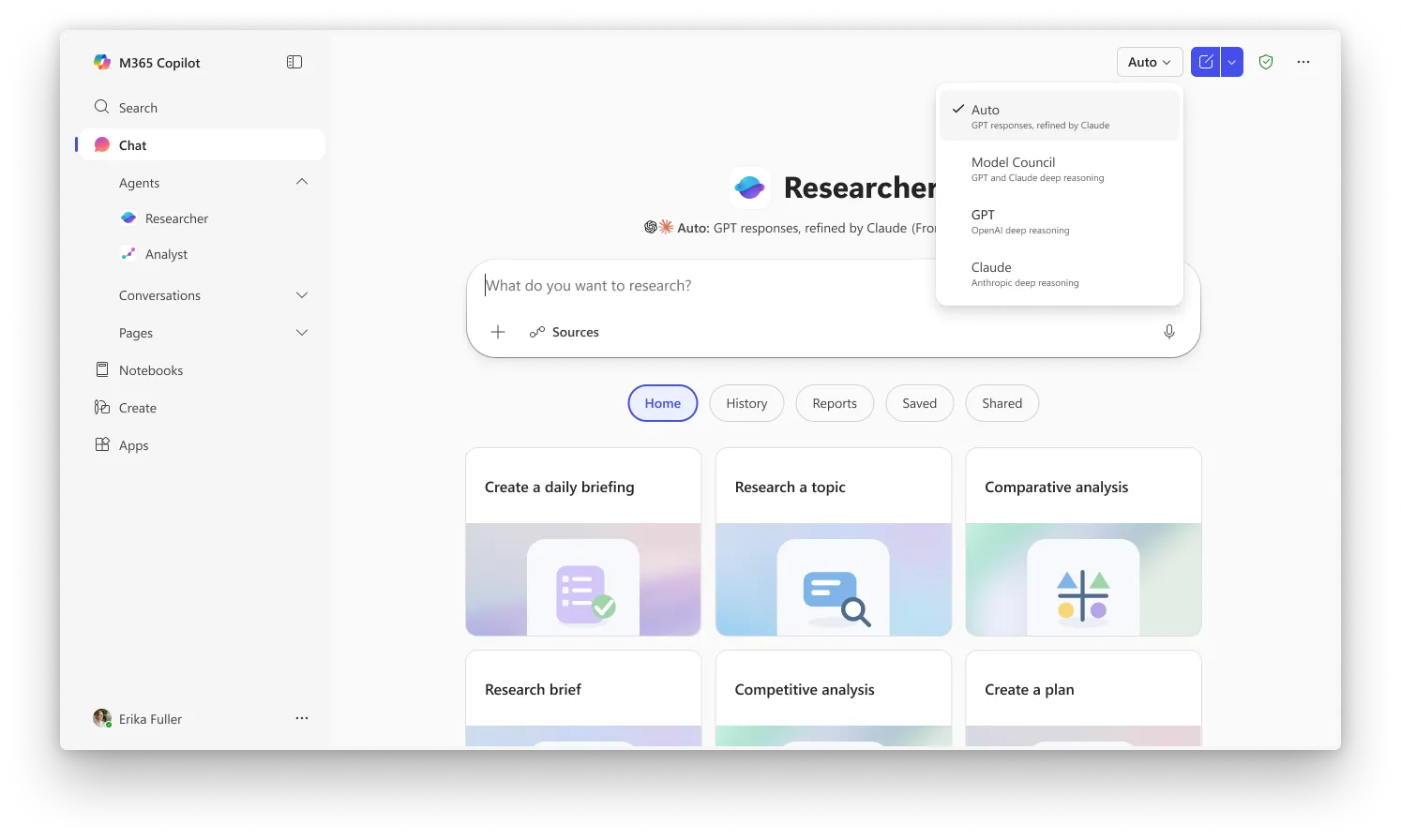
Image: Microsoft
OpenAI và Microsoft có một quan hệ đối tác trị giá hàng tỷ đô la, nhưng chiến cược của Microsoft là không có mô hình đơn lẻ nào có thể giữ vị trí dẫn đầu trong thời gian dài, và giá trị thực nằm ở lớp điều phối—điều tuyến nhiệm vụ đến đúng tổ hợp mô hình hoạt động tốt nhất.
Tuyên bố miễn trừ trách nhiệm: Thông tin trên trang này có thể đến từ bên thứ ba và không đại diện cho quan điểm hoặc ý kiến của Gate. Nội dung hiển thị trên trang này chỉ mang tính chất tham khảo và không cấu thành bất kỳ lời khuyên tài chính, đầu tư hoặc pháp lý nào. Gate không đảm bảo tính chính xác hoặc đầy đủ của thông tin và sẽ không chịu trách nhiệm cho bất kỳ tổn thất nào phát sinh từ việc sử dụng thông tin này. Đầu tư vào tài sản ảo tiềm ẩn rủi ro cao và chịu biến động giá đáng kể. Bạn có thể mất toàn bộ vốn đầu tư. Vui lòng hiểu rõ các rủi ro liên quan và đưa ra quyết định thận trọng dựa trên tình hình tài chính và khả năng chấp nhận rủi ro của riêng bạn. Để biết thêm chi tiết, vui lòng tham khảo
Tuyên bố miễn trừ trách nhiệm.
