AI 模型的發展正加速全球 GPU 需求的成長。隨著大型語言模型(LLM)、AI Agent 與自動化應用不斷擴展,傳統中心化 AI 雲平台逐漸面臨高成本、資源集中與擴展壓力等挑戰。在此背景下,去中心化 GPU 網路成為 Web3 AI 基礎設施的重要探索方向。
Dolphin Network正是在這股趨勢下誕生的 AI 推理網路。其核心目標是將全球分散的 GPU 資源整合為開放式 AI 基礎設施,並透過 POD 激勵機制協調開發者、GPU 節點與網路的互動。
Dolphin Network 的核心架構是什麼?
Dolphin Network 的核心由三大要素組成:AI 推理請求方、GPU 節點網路,以及驗證協調機制。
開發者或應用可向網路提交 AI 推理請求,例如文字生成、聊天推理、模型調用或 AI Agent 任務。網路會根據 GPU 節點狀態、任務需求與資源可用性,動態分配請求至合適節點進行處理。
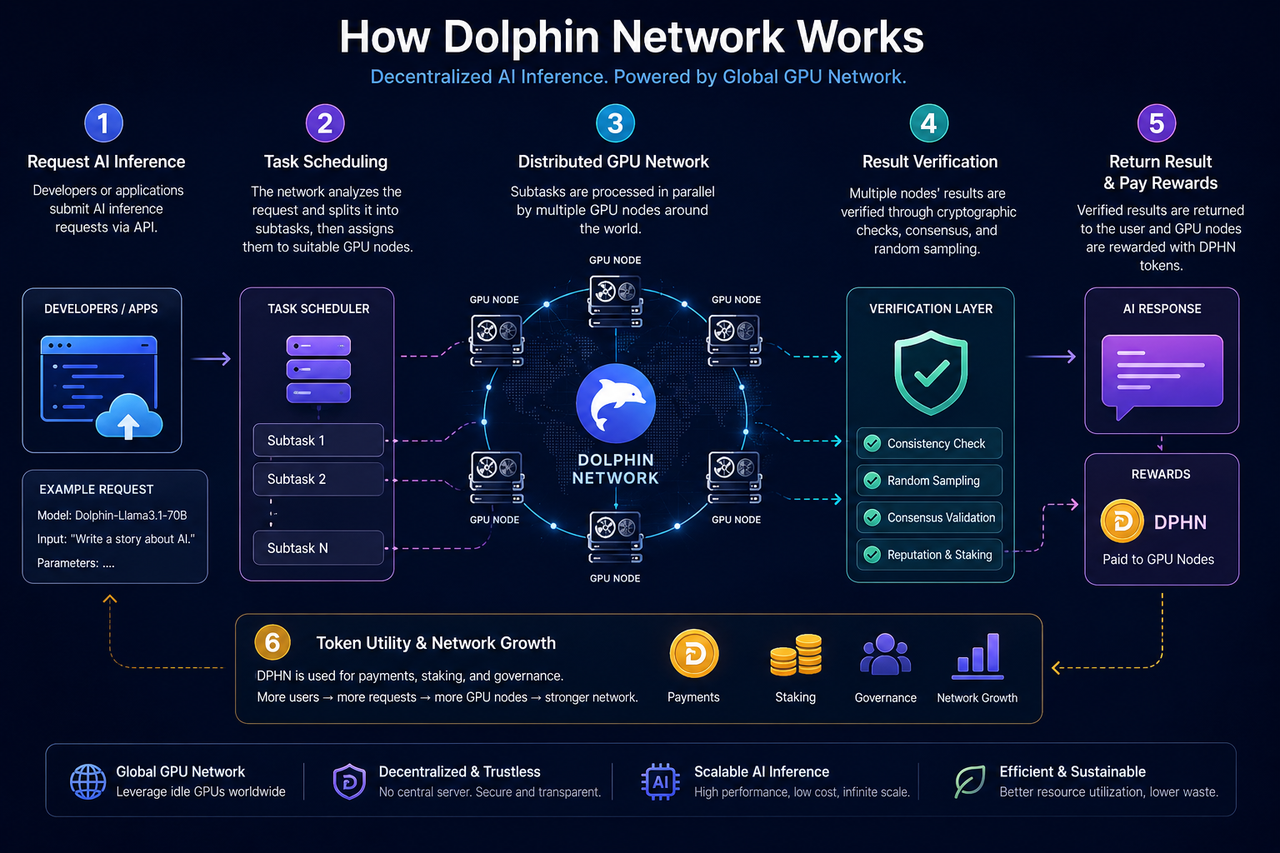
GPU 節點由全球用戶提供。用戶可利用閒置 GPU 加入網路,在本地執行推理任務,並依貢獻獲得代幣獎勵。
為確保結果可信,Dolphin 透過驗證與經濟機制協調節點行為,包括隨機抽樣驗證、任務複核及質押機制等設計。
AI 推理請求如何進入網路?
當開發者調用 Dolphin Network 時,請求會首先進入任務調度層。
此階段主要負責分析任務類型、GPU 需求與模型資源。例如,不同 AI 模型需不同顯存配置、推理速度及運算能力,網路需依節點狀態動態匹配。
在中心化 AI 雲平台中,此流程通常由單一資料中心完成;而在 Dolphin,任務則分配至分布式 GPU 節點網路。
部分任務還可能拆分為多個小型推理請求,以提升整體處理效率與網路並發能力。
GPU 節點如何執行 AI 推理任務?
GPU 節點是 Dolphin Network 的核心運算資源。
節點運行者需部署指定軟體,並允許系統調用本地 GPU 執行 AI 推理任務。任務分發後,節點會下載相關模型或推理參數,在本地完成運算。
任務完成後,節點將推理結果回傳網路,並等待驗證流程確認結果有效。僅通過驗證的任務才能獲得代幣獎勵。
此模式與傳統 GPU 挖礦有所不同。傳統 PoW 網路主要進行雜湊運算,而 Dolphin 的 GPU 節點則執行實際 AI 推理任務,更貼近「可用算力市場」的概念。
Dolphin 如何驗證 AI 推理結果?
AI 推理與一般區塊鏈交易不同,其結果難以透過簡單數學公式直接驗證。因此,Dolphin 需設計額外機制,確保節點不會提交錯誤結果。
常見方法為隨機抽樣驗證,系統隨機選擇部分任務複核,確認多個節點結果是否一致。若節點長期提交異常資料,將被降低信譽或失去獎勵資格。
此外,部分去中心化 AI 網路結合質押機制。節點需抵押一定數量代幣參與網路,若有惡意行為,質押資產將遭受懲罰。
此機制本質上以經濟激勵約束節點行為,提升網路可信度。
Dolphin 與傳統 AI 雲推理有何不同?
傳統 AI 雲平台多依賴大型中心化資料中心,由單一公司控制 GPU 集群、模型部署與 API 服務。
Dolphin 採用開放式 GPU 網路架構。GPU 節點由全球用戶共同提供,開發者可在更開放環境下使用 AI 推理服務,降低對單一平台的依賴。
此外,Dolphin 強調開放式 AI 模型與資源共享。部分網路支持開源模型部署、自訂系統規則及開放式 AI Agent 應用場景。
但分布式 AI 網路亦面臨穩定性、網路延遲及節點品質差異等挑戰,目前仍處於早期發展階段。
Dolphin Network 面臨哪些挑戰?
去中心化 AI 推理網路具備開放性與資源共享優勢,但仍面臨多項現實挑戰。
首先,GPU 節點效能落差大。不同設備的顯存、頻寬與推理能力影響整體網路穩定性。
其次,AI 推理結果驗證仍然複雜。相較於區塊鏈交易,AI 輸出結果具機率性,驗證成本更高。
此外,隨著 AI 模型規模不斷擴大,分布式網路如何高效調度大規模 GPU 集群,也是 AI DePIN 項目亟需解決的關鍵問題。
監管環境亦充滿不確定性。開放式 AI 模型可能涉及資料、版權及內容生成等議題,AI 基礎設施網路需面對長期監管挑戰。
總結
Dolphin Network 結合 AI 與 DePIN,打造去中心化 AI 推理網路,核心目標是透過全球 GPU 節點建構開放式 AI 基礎設施。網路以任務調度、分布式推理、隨機驗證及 DPHN 激勵機制協調開發者與 GPU 節點的關係。
與傳統中心化 AI 雲平台相比,Dolphin 更強調開放性、資源共享及抗審查能力,成為 Web3 AI 基礎設施的重要發展方向。
FAQs
Dolphin 如何利用 GPU 節點?
GPU 持有者可部署節點,貢獻閒置 GPU 資源,執行 AI 推理任務,並獲得 DPHN 獎勵。
Dolphin 的 AI 推理流程包含哪些步驟?
主要涵蓋任務提交、節點調度、GPU 推理執行、結果驗證及獎勵分配等階段。
Dolphin 為何屬於 DePIN 項目?
其核心資源為現實世界 GPU 硬體,並透過代幣激勵協調分布式基礎設施運作。
Dolphin 與傳統 AI 雲平台有何不同?
傳統 AI 雲平台依賴中心化資料中心,Dolphin 則以開放式 GPU 網路提供分布式 AI 推理服務。
DPHN 在網路中的作用?
DPHN 用於 AI 推理支付、節點獎勵、質押及網路經濟激勵。
分享
目錄


相關文章

Solana需要 L2 和應用程式鏈?

Sui:使用者如何利用其速度、安全性和可擴充性?

Morpho vs Aave:深入解析 DeFi 借貸協議的機制與結構差異

Morpho 代幣經濟學深入解析:MORPHO 的應用、分配方式與價值邏輯

USD.AI 效益來源解析:AI 基礎設施貸款如何創造收益
