Nguồn gốc: Heart of the Machine
 Nguồn hình ảnh: Được tạo bởi Unbounded AI
Nguồn hình ảnh: Được tạo bởi Unbounded AI
Trí tuệ nhân tạo đang phát triển nhanh chóng, nhưng có nhiều vấn đề. API tầm nhìn GPT mới của OpenAI khiến mọi người thở dài rằng chân trước rất hiệu quả, và chân sau đang phàn nàn về vấn đề ảo ảnh.
Ảo giác luôn là lỗ hổng chết người của những người mẫu lớn. Do bộ dữ liệu lớn và phức tạp, không thể tránh khỏi việc sẽ có thông tin lỗi thời và sai trong đó, dẫn đến một bài kiểm tra nghiêm ngặt về chất lượng đầu ra. Quá nhiều thông tin lặp đi lặp lại cũng có thể làm sai lệch các mô hình lớn, đây cũng là một dạng ảo ảnh. Nhưng ảo giác không phải là không thể giải quyết. Sử dụng cẩn thận và lọc nghiêm ngặt các bộ dữ liệu trong quá trình phát triển, cũng như xây dựng các bộ dữ liệu chất lượng cao, cũng như tối ưu hóa cấu trúc mô hình và phương pháp đào tạo có thể làm giảm bớt vấn đề ảo ảnh ở một mức độ nhất định.
Có rất nhiều mô hình lớn đang thịnh hành, và chúng có hiệu quả như thế nào trong việc giảm bớt ảo giác? Đây là một bảng xếp hạng tương phản rõ ràng khoảng cách.
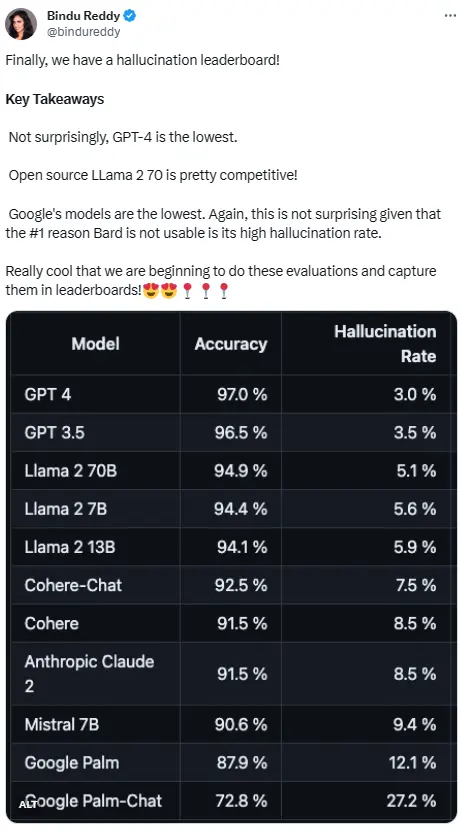 Bảng xếp hạng được xuất bản bởi nền tảng Vectara tập trung vào AI. Bảng xếp hạng đã được cập nhật vào ngày 1 tháng 11 năm 2023 và Vectara cho biết họ sẽ tiếp tục theo dõi các đánh giá ảo giác khi mô hình được cập nhật.
Bảng xếp hạng được xuất bản bởi nền tảng Vectara tập trung vào AI. Bảng xếp hạng đã được cập nhật vào ngày 1 tháng 11 năm 2023 và Vectara cho biết họ sẽ tiếp tục theo dõi các đánh giá ảo giác khi mô hình được cập nhật.
Địa chỉ dự án:
Để xác định bảng xếp hạng này, Vectara đã tiến hành một nghiên cứu tính nhất quán thực tế trên mô hình tóm tắt bằng cách sử dụng nhiều bộ dữ liệu nguồn mở và đào tạo một mô hình để phát hiện ảo giác trong đầu ra LLM. Họ đã sử dụng một mô hình giống như SOTA, và sau đó cung cấp 1.000 tài liệu ngắn cho mỗi LLM này thông qua API công khai và yêu cầu họ tóm tắt từng tài liệu chỉ sử dụng các sự kiện được trình bày trong tài liệu. Trong số 1000 tài liệu này, chỉ có 831 tài liệu được tóm tắt bởi mỗi mô hình và phần còn lại đã bị từ chối bởi ít nhất một mô hình do giới hạn nội dung. Sử dụng 831 tệp này, Vectara đã tính toán độ chính xác tổng thể và tỷ lệ ảo giác cho từng mô hình. Tỷ lệ từ chối phản hồi cho từng mô hình được nêu chi tiết trong cột “Tỷ lệ trả lời”. Không có nội dung nào được gửi đến mô hình chứa nội dung bất hợp pháp hoặc không an toàn, nhưng các từ kích hoạt trong đó đủ để kích hoạt một số bộ lọc nội dung. Những tài liệu này chủ yếu từ kho dữ liệu CNN / Daily Mail.
 Điều quan trọng cần lưu ý là Vectara đánh giá độ chính xác của bản tóm tắt, không phải độ chính xác thực tế tổng thể. Điều này cho phép bạn so sánh phản hồi của mô hình với thông tin được cung cấp. Nói cách khác, tóm tắt đầu ra được đánh giá là “nhất quán thực tế” như tài liệu nguồn. Vì không biết mỗi LLM được đào tạo dựa trên dữ liệu nào, nên không thể xác định ảo giác cho bất kỳ vấn đề cụ thể nào. Ngoài ra, để xây dựng một mô hình có thể xác định liệu một câu trả lời có phải là ảo ảnh mà không có nguồn tham chiếu hay không, vấn đề ảo giác cần được giải quyết và một mô hình lớn bằng hoặc lớn hơn LLM đang được đánh giá cần phải được đào tạo. Do đó, Vectara đã chọn xem xét tỷ lệ ảo giác trong nhiệm vụ tóm tắt, vì sự tương tự như vậy sẽ là một cách tốt để xác định tính hiện thực tổng thể của mô hình.
Điều quan trọng cần lưu ý là Vectara đánh giá độ chính xác của bản tóm tắt, không phải độ chính xác thực tế tổng thể. Điều này cho phép bạn so sánh phản hồi của mô hình với thông tin được cung cấp. Nói cách khác, tóm tắt đầu ra được đánh giá là “nhất quán thực tế” như tài liệu nguồn. Vì không biết mỗi LLM được đào tạo dựa trên dữ liệu nào, nên không thể xác định ảo giác cho bất kỳ vấn đề cụ thể nào. Ngoài ra, để xây dựng một mô hình có thể xác định liệu một câu trả lời có phải là ảo ảnh mà không có nguồn tham chiếu hay không, vấn đề ảo giác cần được giải quyết và một mô hình lớn bằng hoặc lớn hơn LLM đang được đánh giá cần phải được đào tạo. Do đó, Vectara đã chọn xem xét tỷ lệ ảo giác trong nhiệm vụ tóm tắt, vì sự tương tự như vậy sẽ là một cách tốt để xác định tính hiện thực tổng thể của mô hình.
Phát hiện địa chỉ mô hình ảo ảnh:
Ngoài ra, LLM đang ngày càng được sử dụng nhiều hơn trong các đường ống RAG (Retri Augmented Generation) để trả lời các truy vấn của người dùng, chẳng hạn như tích hợp Bing Chat và Google Chat. Trong hệ thống RAG, mô hình được triển khai như một công cụ tổng hợp kết quả tìm kiếm, vì vậy bảng xếp hạng cũng là một chỉ báo tốt về độ chính xác của mô hình khi được sử dụng trong hệ thống RAG.
Do hiệu suất tuyệt vời liên tục của GPT-4, có vẻ như nó có tỷ lệ ảo giác thấp nhất. Tuy nhiên, một số cư dân mạng cho rằng ông rất ngạc nhiên khi GPT-3.5 và GPT-4 không cách nhau quá xa.
 LLaMA 2 có hiệu suất tốt hơn sau GPT-4 và GPT-3.5. Nhưng hiệu suất của mô hình lớn của Google thực sự không đạt yêu cầu. Một số cư dân mạng cho rằng Bộ NN&PTNT thường sử dụng cụm từ “Tôi vẫn đang tập luyện” để đưa ra những câu trả lời sai.
LLaMA 2 có hiệu suất tốt hơn sau GPT-4 và GPT-3.5. Nhưng hiệu suất của mô hình lớn của Google thực sự không đạt yêu cầu. Một số cư dân mạng cho rằng Bộ NN&PTNT thường sử dụng cụm từ “Tôi vẫn đang tập luyện” để đưa ra những câu trả lời sai.
 Với bảng xếp hạng như vậy, chúng ta có thể đánh giá trực quan hơn về ưu điểm và nhược điểm của các mô hình khác nhau. Vài ngày trước, OpenAI đã ra mắt GPT-4 Turbo, không, một số cư dân mạng ngay lập tức đề xuất cập nhật nó trên bảng xếp hạng.
Với bảng xếp hạng như vậy, chúng ta có thể đánh giá trực quan hơn về ưu điểm và nhược điểm của các mô hình khác nhau. Vài ngày trước, OpenAI đã ra mắt GPT-4 Turbo, không, một số cư dân mạng ngay lập tức đề xuất cập nhật nó trên bảng xếp hạng.
 Chúng ta sẽ xem bảng xếp hạng tiếp theo sẽ như thế nào và liệu có những thay đổi đáng kể hay không.
Chúng ta sẽ xem bảng xếp hạng tiếp theo sẽ như thế nào và liệu có những thay đổi đáng kể hay không.
Link tham khảo:
Tuyên bố miễn trừ trách nhiệm: Thông tin trên trang này có thể đến từ bên thứ ba và không đại diện cho quan điểm hoặc ý kiến của Gate. Nội dung hiển thị trên trang này chỉ mang tính chất tham khảo và không cấu thành bất kỳ lời khuyên tài chính, đầu tư hoặc pháp lý nào. Gate không đảm bảo tính chính xác hoặc đầy đủ của thông tin và sẽ không chịu trách nhiệm cho bất kỳ tổn thất nào phát sinh từ việc sử dụng thông tin này. Đầu tư vào tài sản ảo tiềm ẩn rủi ro cao và chịu biến động giá đáng kể. Bạn có thể mất toàn bộ vốn đầu tư. Vui lòng hiểu rõ các rủi ro liên quan và đưa ra quyết định thận trọng dựa trên tình hình tài chính và khả năng chấp nhận rủi ro của riêng bạn. Để biết thêm chi tiết, vui lòng tham khảo
Tuyên bố miễn trừ trách nhiệm.
