蜜拉喬娃維琪用AI做出「滿分專案」?開發者實測:是真有料還是誇大炒作?

蜜拉喬娃維琪參與開發的 AI 記憶系統 MemPalace 宣稱測試滿分而爆紅,卻遭社群踢爆測試涉嫌作弊與數據誤導。實測發現成效誇大且有大量錯誤,團隊已承認瑕疵並著手修復中。
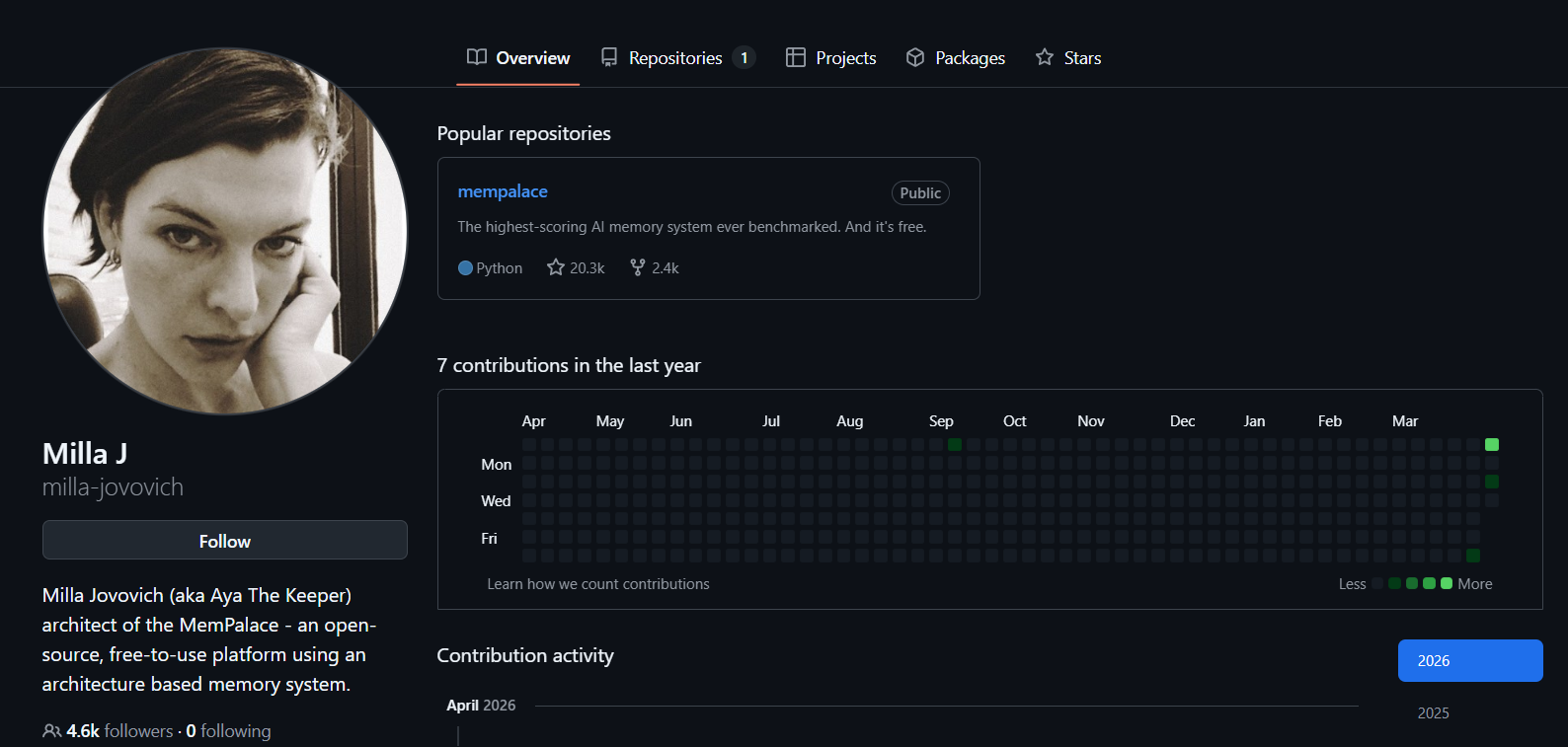
蜜拉喬娃維琪打造AI記憶宮殿,引發外界關注
昨天(4/7)AI 圈有個大新聞是,以《惡靈古堡》、《第五元素》聞名的好萊塢女星蜜拉·喬娃維琪(Milla Jovovich),與開發者 Ben Sigman 使用 Claude Code 輔助開發出「MemPalace」開源 AI 記憶系統。
一時間,「好萊塢巨星跨界做出滿分專案」的說法廣泛流傳,MemPalace 至今在 GitHub 上也獲得超過 2 萬顆星星,但很快地就引發開發者社群質疑:是真的有料還是炒作?
先來說一下 MemPalace 誕生的動機,官方文件稱是想解決目前 AI 系統使用者與 AI 的對話內容、決策過程與架構討論通常會在工作階段結束後消失,導致數個月的心血歸零的限制。
為解決這個問題,MemPalace 採用空間架構來儲存記憶,將資訊明確歸類至代表人員或專案的翼區,以及走廊、房間與抽屜等不同層級的結構中,保留對話原文供後續語意檢索。
開發團隊宣稱,MemPalace 在長效記憶評估基準 LongMemEval 中獲得 100% 的完美成績,並且在不呼叫任何外部 API 的情況下達到 96.6% 的準確率,而且能完全在本地端運行,不需訂閱雲端服務,並搭載號稱能達到 30 倍無損壓縮的 AAAK 方言系統。
圖源:GitHub 美國電影明星蜜拉喬娃維琪打造AI記憶宮殿,引發外界關注
同業與社群齊質疑,測試方法與宣傳存瑕疵
不過,MemPalace 號稱 LongMemEval 滿分的成績,很快就引來了同業質疑。
同樣是製作 AI 記憶系統的 PenfieldLabs 指出,MemPalace 宣稱在 LoCoMo 資料集獲得滿分,在數學上不可能發生,因為該資料集的標準答案本身就包含 99 個錯誤。
PenfieldLabs 分析發現,MemPalace 的 100% 成績來自於將檢索數量設定為 50 次,但測試資料集對話的最高階段數僅有 32 次,這代表系統直接繞過檢索階段,將所有資料交給 AI 模型閱讀。
針對 LongMemEval 的 100% 成績,開發團隊被發現是針對開發集中出錯的 3 個特定問題,撰寫專屬修復程式碼,存在針對測試集作弊的嫌疑。

圖源:Reddit同業PenfieldLabs 指出,MemPalace 宣稱在 LoCoMo 資料集獲得滿分,在數學上不可能發生
GitHub使用者實測,基準測試有誤導成分
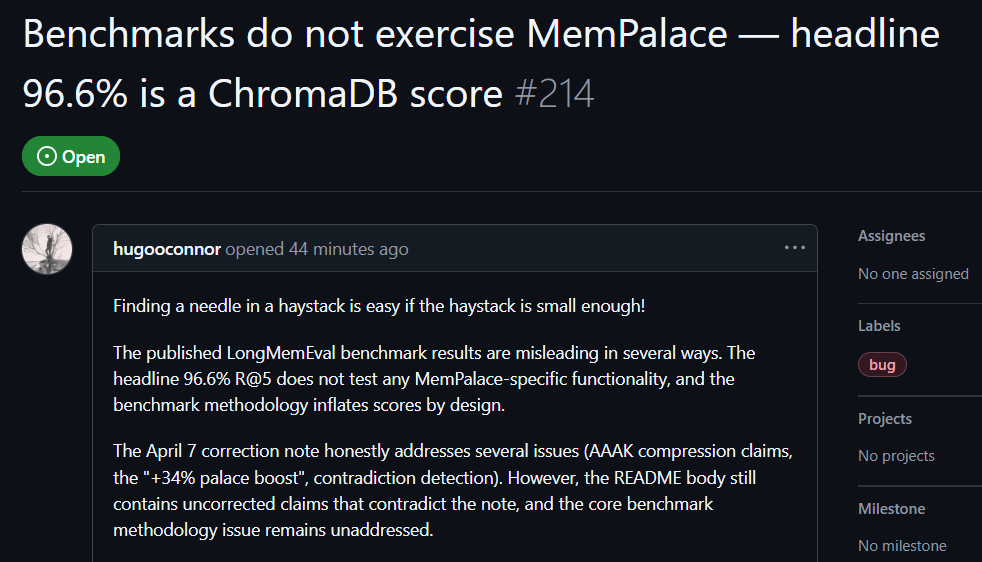
GitHub 使用者 hugooconnor 則在實測後評論,MemPalace 宣稱高達 96.6% 的檢索準確率,實際上完全沒有使用到 MemPalace 標榜的記憶宮殿架構。hugooconnor 稱,他們的測試單純呼叫底層資料庫 ChromaDB 的預設功能,完全沒有牽涉專案強調的翼區、房間或抽屜等分類邏輯。
hugooconnor 測試後發現,當系統真正啟用這些記憶宮殿的專屬分類邏輯時,檢索成績反而出現衰退。以房間模式為例,準確率下降至 89.4%,而啟用 AAAK 壓縮技術後,準確率更跌至 84.2%,兩者皆低於預設資料庫表現。
hugooconnor 也批評了測試方法,MemPalace 的測試環境刻意把每個問題的檢索範圍,縮小至約 50 個對話階段,在極小的樣本庫中尋找答案過於簡單。
若把範圍擴大到真實情境的 19,000 多個對話階段,傳統關鍵字搜尋的準確率會暴跌至 30%,顯示 MemPalace 目前的測試方式掩蓋真實的搜尋難題。
圖源:GitHub GitHub使用者實測,MemPalace基準測試有誤導成分
同時,雖然開發團隊已經發布更正聲明,承認 AAAK 技術確實驗證為有損壓縮,並承諾會根據社群的嚴厲批評修正說明文件與系統設計。但專案的主說明文件依然保留多項未經修正的誇大說法,包含宣稱 30 倍無損壓縮與 34% 檢索提升,且與其他競爭對手的比較圖表也完全缺乏來源出處。
MemPalace原始碼面臨多項Bug
隨著越來越多開發者下載測試,目前 GitHub 平台上出現大量關於 MemPalace 原始碼的 Bug 回報。
使用者 cktang88 列出多項嚴重瑕疵,包含壓縮指令無法運作並導致系統崩潰、摘要字數計算邏輯錯誤、挖掘房間的統計數據不準確,以及伺服器在每次呼叫時會將所有詮釋資料載入記憶體中,造成嚴重的資源消耗問題。
其他被指出的問題,還包括系統將開發者的家庭成員名稱硬性寫入預設設定檔中,以及查詢狀態時存在 1 萬筆資料的強制顯示上限。
針對這些問題,開源社群已經開始積極修復。**使用者 adv3nt3 提交多項修復請求,包含修正挖掘統計數據、移除預設的家庭成員名稱,以及延遲知識圖譜的初始化時間。**開發團隊後續也承認這些錯誤,正透過社群協作逐步解決程式碼的問題。
蜜拉喬娃維琪Vibe Coding很酷,行銷方式不酷
對於 MemPalace 這個專案,Hacker News 網友 darkhanakh 下了一個結論:MemPalace 給人一種 OpenClaw 的既視感,也就是人為操縱基準測試(benchmark)結果使其看起來完美無瑕,然後再將其包裝成某種重大突破來行銷。
他認為,MemPalace 的底層技術可能確實很有意思,但在測試方法帶有這類瑕疵的情況下,還主打「史上公開最高分」來宣傳,實在不太妥當,「不過,蜜拉喬娃維琪在玩 Vibe Coding 這件事,我想還是挺酷的啦。」
延伸閱讀:
AI寫程式出包!超商即期品App「惜食獵人」爆資安問題,家中GPS全裸奔