GPU推理提速4倍,256K上下文全球最長:無問芯穹刷新大模型優化記錄
想用大模型賺錢? 這個實力強勁的新面孔決定先把推理成本打下來。
原文來源:機器之心
 圖片來源:由無界 AI生成
圖片來源:由無界 AI生成
大模型業務到底多燒錢? 前段時間,華爾街日報的一則報導給出了參考答案。
報導顯示,微軟的 GitHub Copilot 業務(背後由 OpenAI 的 GPT 大模型支撐)雖然每月收費 10 美元,但平均還是要為每個使用者倒貼 20 美元。 可見當前 AI 服務提供者們正面臨著嚴峻的經濟賬挑戰 —— 這些服務不僅構建成本高昂,運營成本也非常高。
有人比喻說:「使用 AI 總結電子郵件,就像是讓蘭博基尼送披薩外賣。」
對此,OpenAI 算過一筆更詳細的賬:當上下文長度為 8K 時,每 1K 輸入 token 的成本為 3 美分,輸出的成本為 6 美分。 目前,OpenAI 擁有 1.8 億使用者,每天收到的查詢數量超過 1000 萬次。 這樣算來,為了運營 ChatGPT 這樣的模型,OpenAI 每天都需要在必要的計算硬體上投入大約 700 萬美元,可以說是貴得嚇人。
 **降低 LLM 的推理成本勢在必行,而提升推理速度成為一條行之有效的關鍵路徑。 **
**降低 LLM 的推理成本勢在必行,而提升推理速度成為一條行之有效的關鍵路徑。 **
實際上,研究社區已經提出了不少用於加速 LLM 推理任務的技術,包括 DeepSpeed、FlexGen、vLLM、OpenPPL、FlashDecoding 和 TensorRT-LLM 等。 這些技術自然也各有優勢和短板。 其中,FlashDecoding 是 FlashAttention 作者、斯坦福大學團隊的 Tri Dao 等人在上個月提出的一種 state-of-the-art 方法,它通過並行載入數據,大幅提升了 LLM 的推理速度,被認為極具潛力。 但與此同時,它也引入了一些不必要的計算開銷,因此依然存在很大的優化空間。
為了進一步解決問題,近日,**來自無問芯穹(Infinigence-AI)、清華大學和上海交通大學的聯合團隊提出了一種新方法 FlashDecoding++,不僅能帶來比之前方法更強的加速能力(可以將 GPU 推理提速 2-4 倍),更重要的是還同時支援 NVIDIA 和 AMD 的 GPU! 它的核心思想是通過異步方法實現注意力計算的真正並行,並針對「矮胖」矩陣乘優化加速 Decode 階段的計算。 **
 論文位址:
論文位址:
將 GPU 推理提速 2-4 倍,
**FlashDecoding++ 是怎麼做到的? **
LLM 推理任務一般為輸入一段文字(token),通過 LLM 模型計算繼續生成文字或其他形式的內容。
LLM 的推理計算可被分為 Prefill 和 Decode 兩個階段,其中 Prefill 階段通過理解輸入文字,生成第一個 token; Decode 階段則順序輸出後續 token。 在兩個階段,LLM 推理的計算可被分為注意力計算和矩陣乘計算兩個主要部分。
對於注意力計算,現有工作如 FlashDecoding 切分注意力計算中的 softmax 算子實現並行載入數據。 這一方法由於需要在不同部分 softmax 同步最大值,在注意力計算中引入了 20% 的計算開銷。 而對於矩陣乘計算,在Decode階段,左乘矩陣多表現為「矮胖」矩陣,即其行數一般不大(如 <=8),現有 LLM 推理引擎通過補 0 將行數擴充到 64 從而利用 Tensor Core 等架構加速,從而導致大量的無效計算(乘 0)。
為解決上述問題,**「FlashDecoding++」的核心思想在於,通過異步方法實現注意力計算的真正並行,並針對「矮胖」矩陣乘優化加速 Decode 階段的計算。 **
異步並行部分 softmax 計算
 圖 1 異步並行部分 softmax 計算
圖 1 異步並行部分 softmax 計算
先前工作對每個部分 softmax 計算求輸入最大值作為縮放係數,避免 softmax 計算中 e 指數的溢出,這就導致了不同部分 softmax 計算的同步開銷(圖 1 (a)(b))。
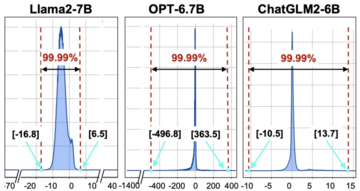
「FlashDecoding++」指出,對於大部分 LLM,其 softmax 的輸入分佈較為集中。 如圖 2 所示,Llama2-7B 的 softmax 輸入 99.99% 以上集中在 [-16.8, 6.5] 這個區間。 因此,「FlashDecoding++」提出在部分 softmax 計算時使用一個固定的最大值(圖 1 (c)),從而避免了不同部分 softmax 計算間的頻繁同步。 而當小概率發生的輸入超出給定範圍時,「FlashDecoding++」對這一部分的 softmax 計算退化為原先的計算方法。
「矮胖」矩陣乘的優化
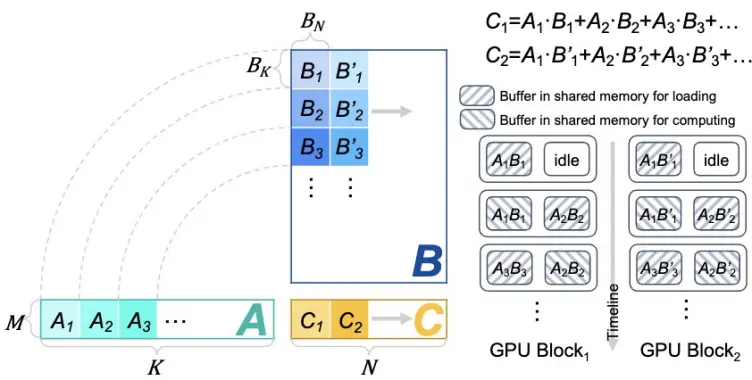 圖 3 「矮胖」矩陣乘切分與雙緩存機制
圖 3 「矮胖」矩陣乘切分與雙緩存機制
由於 Decode 階段的輸入為一個或幾個 token 向量,因此該階段的矩陣乘表現為「矮胖」形狀。 以矩陣 A×B=C 為例,A 與 B 矩陣的形狀為 M×K 與 K×N,「矮胖」矩陣乘即 M 較小的情況。 「FlashDecoding++」指出「矮胖」矩陣乘一般緩存受限,並提出雙緩存機制等優化手段進行加速(圖 3)。
 圖 4 自適應矩陣乘實現
圖 4 自適應矩陣乘實現
此外,「FlashDecoding++」進一步指出,在 LLM 推理階段,針對特定模型,N 和 K 的取值固定。 因此,「FlashDecoding++」會根據 M 的大小,自適應選取矩陣乘的最優實現。
將 GPU 推理提速 2-4 倍
 圖 5 「FlashDecoding++」NVIDIA 與 AMD 平臺 LLM 推理(Llama2-7B模型,batchsize=1)
圖 5 「FlashDecoding++」NVIDIA 與 AMD 平臺 LLM 推理(Llama2-7B模型,batchsize=1)
目前,「FlashDecoding++」可以實現 NVIDIA 與 AMD 等多款 GPU 後端的 LLM 推理加速(圖 5)。 通過加速 Prefill 階段的首 token 生成速度,以及 Decode 階段每個 token 的生成速度,「FlashDecoding++」可以在長、短文本的生成上均取得加速效果。 **相較於 FlashDecoding,「FlashDecoding++」在 NVIDIA A100 上的推理平均加速 37%,並在 NVIDIA 和 AMD 的多 GPU 後端上相較於 Hugging Face 實現加速多達 2-4 倍。 **
AI 大模型創業新秀:無問芯穹
該研究的三位共同一作分別是無問芯穹首席科學家、上海交通大學副教授戴國浩博士,無問芯穹研究實習生、清華大學碩士生洪可,無問芯穹研究實習生、上海交通大學博士生許珈銘。 通訊作者為上海交通大學戴國浩教授和清華大學電子工程系主任汪玉教授。
創立於 2023 年 5 月的無問芯穹,目標是打造大模型軟硬體一體化最佳解決方案,目前 FlashDecoding++ 已被集成於無問芯穹的大模型計算引擎「Infini-ACC」中。 在「Infini-ACC」的支援下,無問芯穹正在開發一系列大模型軟硬體一體化的解決方案,其中包含大模型「無穹天權(Infini-Megrez)」、軟硬體一體機等。
據瞭解,「Infini-Megrez」在處理長文本方面表現非常出色,將可處理的文本長度破紀錄地提升到了 256k token,實測處理大約 40 萬字的一整本《三體 3:死神永生》也不成問題。 這是當前的大模型所能處理的最長文本長度。
 此外,「Infini-Megrez」大模型在 C (中)、MMLU (英)、CMMLU (中)、AGI 等數據集上均取得了第一梯隊演算法性能,並依託「Infini-ACC」計算引擎持續進化中。
此外,「Infini-Megrez」大模型在 C (中)、MMLU (英)、CMMLU (中)、AGI 等數據集上均取得了第一梯隊演算法性能,並依託「Infini-ACC」計算引擎持續進化中。